
[Paper Review] Make Me a BNN: A Simple Strategy for Estimating Bayesian Uncertainty from Pre-trained Model
이 포스팅은 “Make Me a BNN: A Simple, Scalable Strategy for Estimating Bayesian Uncertainty” 논문을 읽고 ABNN의 핵심 아이디어에 대해 정리한 글입니다.
Introduction
딥러닝 신경망(DNN)은 이미지 분류, 자연어 처리 등 수많은 분야에서 인간을 뛰어넘는 성능을 보여주고 있습니다. 하지만 이런 DNN에게는 한 가지 약점이 있습니다. 바로 자신이 얼마나 확신하는지, 즉 ‘불확실성(Uncertainty)’을 제대로 표현하지 못한다는 것입니다. 모델이 “이건 99% 확률로 고양이야”라고 말해도, 실제로는 생전 처음 보는 동물일 수 있습니다.
이는 자율 주행 자동차나 의료 AI처럼 안전이 무엇보다 중요한 분야에서 치명적인 문제가 될 수 있습니다. 모델이 자신의 예측을 얼마나 신뢰할 수 있는지 스스로 아는 능력, 즉 불확실성 정량화가 필수적인 이유입니다.
이 문제를 해결하기 위해 베이지안 신경망(BNN) 이 있지만, 훈련이 매우 불안정하고 계산 비용이 높아 규모가 매우 큰 최신 모델들에 적용하기 어렵습니다. 또 다른 대안인 Deep Ensembles 은 성능은 좋지만, 모델 여러 개를 처음부터 훈련시켜야 해 많은 시간과 자원을 소모합니다.
이러한 딜레마 속에서, “이미 잘 훈련된 DNN을 최소한의 비용으로 BNN으로 바꿀 수는 없을까?” 라는 질문에 대한 아이디어가 바로 ABNN(Adaptable Bayesian Neural Network) 입니다.
What is ABNN?
ABNN의 핵심은 간단합니다. “처음부터 만들지 말고, 이미 잘하는 녀석을 적응시키자.”
ABNN은 이미 학습이 완료된 강력한 DNN을 가져와서, 사후 방식으로 구조를 살짝 바꾸고 아주 잠깐만 더 훈련시켜 불확실성까지 측정할 수 있는 BNN으로 변신시키는 전략입니다.
How ABNN Works: A 3-Step Process
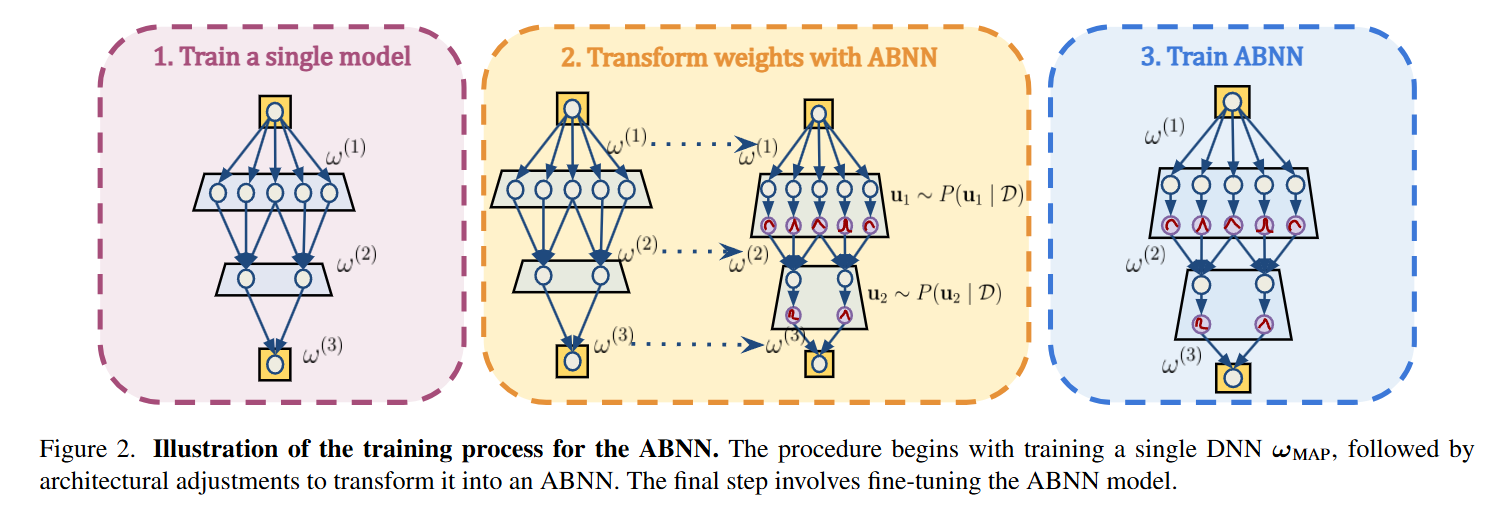
ABNN은 위와 같은 3단계의 간단한 과정을 통해 DNN을 BNN으로 변환합니다.
Step 1: Train a single model
단일 모델을 먼저 학습시킵니다. 보통 ResNet, ViT처럼 이미 성능이 검증된 강력한 사전 훈련(pre-trained) 모델에서 시작합니다.
Step 2: Transform weights with ABNN
그다음, 모델 내부에 있는 모든 정규화 레이어(Batch Normalization, Layer Normalization 등)를 찾아내어 BNL(Bayesian Normalization Layer)이라는 특수 부품으로 교체합니다.
Step 3: Train ABNN
모델 전체를 다시 훈련하는 것은 엄청난 낭비입니다. ABNN은 새로 교체한 BNL 부품의 파라미터만 미세 조정(fine-tuning) 합니다.
추가적으로, 이 과정을 3~4번 반복하여 여러 개의 ABNN 모델을 만들어 이 모델들의 예측을 종합(앙상블)하면 더 안정적이고 신뢰도 높은 불확실성을 얻을 수 있다고 논문에서는 이야기합니다.
How Uncertainty is Generated
그렇다면 BNL이라는 부품은 어떻게 불확실성을 만들어낼까요? 비밀은 의도적인 무작위성 주입에 있습니다.
- Traditional Normalization: “출력 = $\gamma$ * 정규화된 입력 + $\beta$” 라는 고정된 계산을 수행합니다. $\gamma$와 $\beta$ 는 학습된 고정값입니다.
- BNL: 출력 = ($\gamma$ * (1 + 랜덤_노이즈)) * 정규화된 입력 + $\beta$ 라는 확률적인 계산을 수행합니다.
BNL은 학습된 스케일링 파라미터 $\gamma$에 매번 새로운 가우시안 랜덤 노이즈를 곱해줍니다.
따라서 동일한 데이터를 여러 번 입력해도 매번 다른 예측 결과가 나오게 됩니다. 이 결과값의 분산을 측정하면, 그것이 바로 모델의 불확실성이 됩니다. 결과가 거의 흔들리지 않으면 모델이 확신하는 것이고, 크게 흔들린다면 헷갈려 하고 있다는 뜻입니다.
BNL Code
실제 PyTorch 코드를 보면 이 메커니즘을 더 명확하게 이해할 수 있습니다.
import torch
import torch.nn as nn
class BNL(nn.Module):
def __init__(self, num_features):
super(BNL, self).__init__()
if isinstance(num_features, int):
num_features = (num_features,)
self.num_features = num_features
# 1. 호환성을 위해 기존 Norm Layer와 동일한 이름 사용
self.weight = nn.Parameter(torch.ones(num_features)) # 감마(gamma) 역할
self.bias = nn.Parameter(torch.zeros(num_features)) # 베타(beta) 역할
self.eps = 1e-5
def forward(self, x):
# BatchNorm/LayerNorm 방식에 따라 평균/분산 계산 범위를 다르게 설정
if len(self.num_features) == 1: # BatchNorm-like
mean = x.mean([0, 2, 3], keepdim=True)
var = x.var([0, 2, 3], keepdim=True)
else: # LayerNorm-like
mean = x.mean(dim=tuple(range(x.dim())[1:]), keepdim=True)
var = x.var(dim=tuple(range(x.dim())[1:]), keepdim=True)
# 2. 표준 정규화 수행
x_normalized = (x - mean) / torch.sqrt(var + self.eps)
# 3. ✨ 불확실성 주입 ✨
# 가우시안 분포에서 랜덤 노이즈 생성
noise = torch.randn(self.weight.shape, device=x.device)
# 학습된 weight(감마)에 노이즈를 적용하여 매번 다른 값을 만듦
gamma_noisy = self.weight * (1 + noise)
# 4. 입력 텐서에 맞게 차원을 조절하고 최종 출력 계산
if x.dim() == 4:
gamma_noisy = gamma_noisy.view(1, -1, 1, 1)
bias = self.bias.view(1, -1, 1, 1)
elif x.dim() == 2:
gamma_noisy = gamma_noisy.view(1, -1)
bias = self.bias.view(1, -1)
Advantages of ABNN
- 압도적인 효율성 (Efficiency): 딥 앙상블처럼 모델 전체를 학습할 필요 없이, 일부 레이어만 잠깐 미세 조정하므로 시간과 계산 자원을 크게 절약합니다.
- 높은 호환성 (Compatibility): 대부분의 최신 DNN 아키텍처는 정규화 레이어를 포함하므로, 어떤 모델이든 쉽게 BNN으로 변환할 수 있습니다.
- 안정적인 훈련 (Stable Training): 처음부터 BNN을 학습할 때 발생하는 불안정성 문제를 피할 수 있습니다.
- 경쟁력 있는 성능 (Competitive Performance): 이렇게 간단하고 효율적인 방법임에도 불구하고, 기존의 복잡한 방법론들과 동등하거나 더 나은 불확실성 예측 성능을 보여줍니다.
Conclusion
ABNN은 DNN의 뛰어난 예측 성능과 BNN의 신뢰도 높은 불확실성 추정 능력 사이의 간극을 잇는 매우 실용적이고 우아한 해결책입니다. 복잡한 이론이나 막대한 계산 자원 없이, 간단한 ‘부품 교체’와 ‘Fine Tuning’만으로 모델을 더 똑똑하고 겸손하게(Uncertainty) 만들 수 있다는 점에서 매우 인상적인 접근법이라고 할 수 있습니다.
댓글남기기