DiT : Scalable Diffusion Models with Transformers
이 포스팅은 DiT (Diffusion Transformer)를 공부하며
통계학적인 관점에서 핵심 개념을 정리한 글입니다.
1. Introduction
최근 디퓨전 모델은 이미지 생성 분야에서 중요한 역할을 하는 생성 모델로 자리 잡았습니다.
특히 DDPM (Ho et al., 2020) 이후,
노이즈를 점진적으로 제거하는 방식의 생성 모델이 높은 성능을 보이며 빠르게 발전했습니다.
이후 DDIM (Song et al., 2021)은
샘플링 방식을 개선하여 더 빠른 생성이 가능하도록 하였으며,
Latent Diffusion Models (Rombach et al., 2022)는
이미지를 압축된 latent 공간에서 처리함으로써 계산 효율을 크게 개선하였고,
스테이블 디퓨전과 같은 실제 서비스 모델의 기반이 되었습니다.
이러한 흐름 속에서 등장한 DiT (Peebles & Xie, 2023)는
기존 diffusion 모델의 구조를 크게 바꾸기보다는,
backbone을 CNN(U-Net)에서 Transformer로 확장한 모델입니다.
DiT를 어떻게 보면 좋을까?
DiT는 완전히 새로운 diffusion 모델이라기보다는,
다음과 같이 이해하는 것이 자연스럽습니다.
- diffusion의 기본 구조는 그대로 유지됩니다
- 학습 방식 (noise prediction)도 동일합니다
- 단지 이를 구현하는 모델을 Transformer로 변경합니다
즉,
\[\text{DiT} = \text{Diffusion Model} + \text{Transformer}\]라고 볼 수 있습니다.
이 글에서 볼 내용
이 글에서는 DiT를 이해하기 위해 다음 흐름으로 정리하였습니다.
- diffusion model의 기본 구조
- DDPM과 DDIM의 차이
- DiT가 기존 구조에서 무엇을 바꿨는지
2. Diffusion Model 기본 구조
Diffusion model은 데이터를 점진적으로 노이즈화한 뒤,
이를 다시 복원하는 방식의 생성 모델입니다.
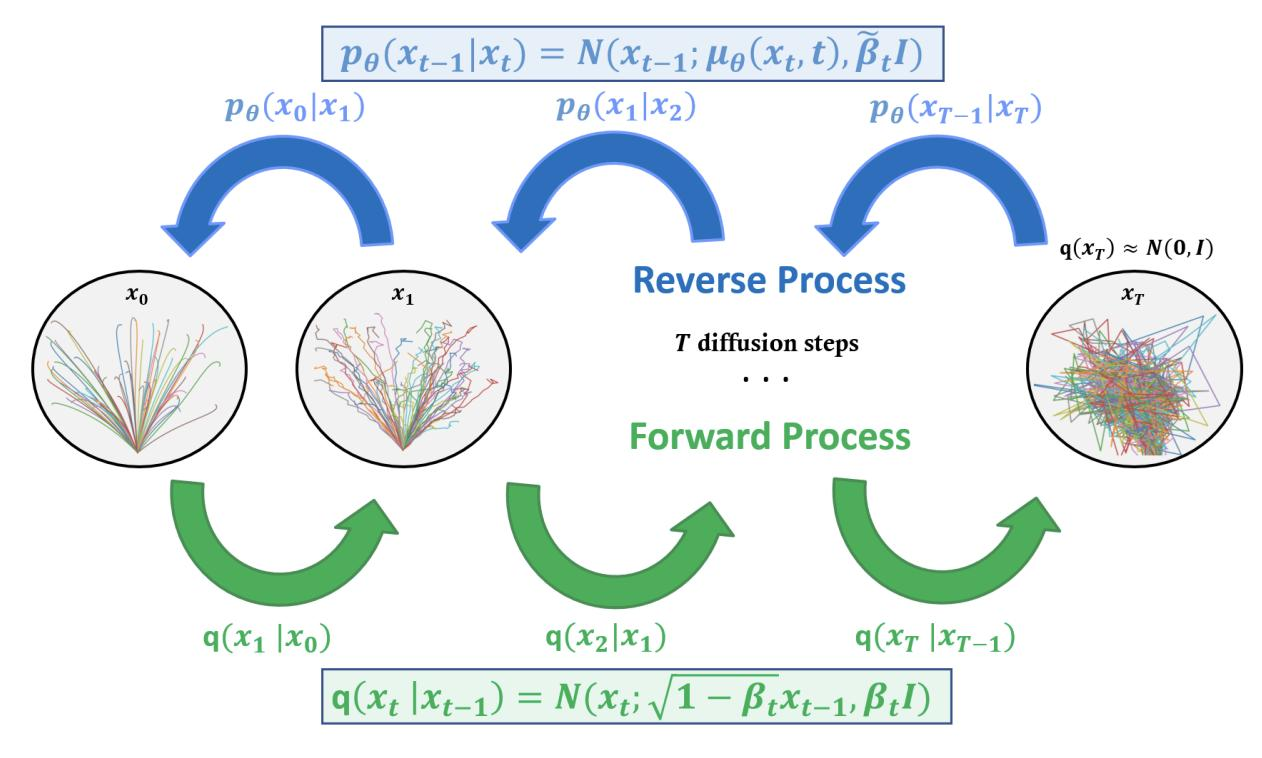
Figure 1. Diffusion model의 forward(노이즈 추가)와 reverse(복원) 과정
위 그림(Figure 1)과 같이 diffusion 모델은 데이터를 점진적으로 노이즈화한 뒤,
이를 다시 복원하는 구조를 가집니다.
2.1 Forward Process
\[x_t = \sqrt{\bar\alpha_t} x_0 + \sqrt{1-\bar\alpha_t} \epsilon\]이 식은 시간 $ t $에서의 데이터 $ x_t $가
원본 데이터 $ x_0 $와 Gaussian noise의 조합으로 표현된다는 것을 의미합니다.
- $ x_0 $: 원본 데이터
- $ \epsilon \sim \mathcal{N}(0, I) $: Gaussian noise
- $ \bar{\alpha}t = \prod{s=1}^{t}(1 - \beta_s) $: 누적 계수
즉,
- 원본 데이터에 점점 더 많은 노이즈가 섞이게 되고
- 시간이 지날수록 데이터는 점점 무작위 노이즈에 가까워집니다
3. DDPM vs DDIM
Diffusion 모델에서는
학습과 샘플링을 구분해서 이해하는 것이 중요합니다.

Figure 2. DDPM의 stochastic sampling과 DDIM의 deterministic trajectory 비교
Figure 2에서 볼 수 있듯이, DDPM은 stochastic한 경로를 따르는 반면
DDIM은 deterministic한 trajectory를 사용합니다.
4. DiT (Diffusion Transformer)
이제 핵심인 DiT를 살펴보겠습니다.
4.2 구조 개요
DiT는 다음과 같은 과정을 거칩니다.
- 이미지 → patch로 분할
- patch → token으로 변환
- Transformer 적용
- noise prediction 출력
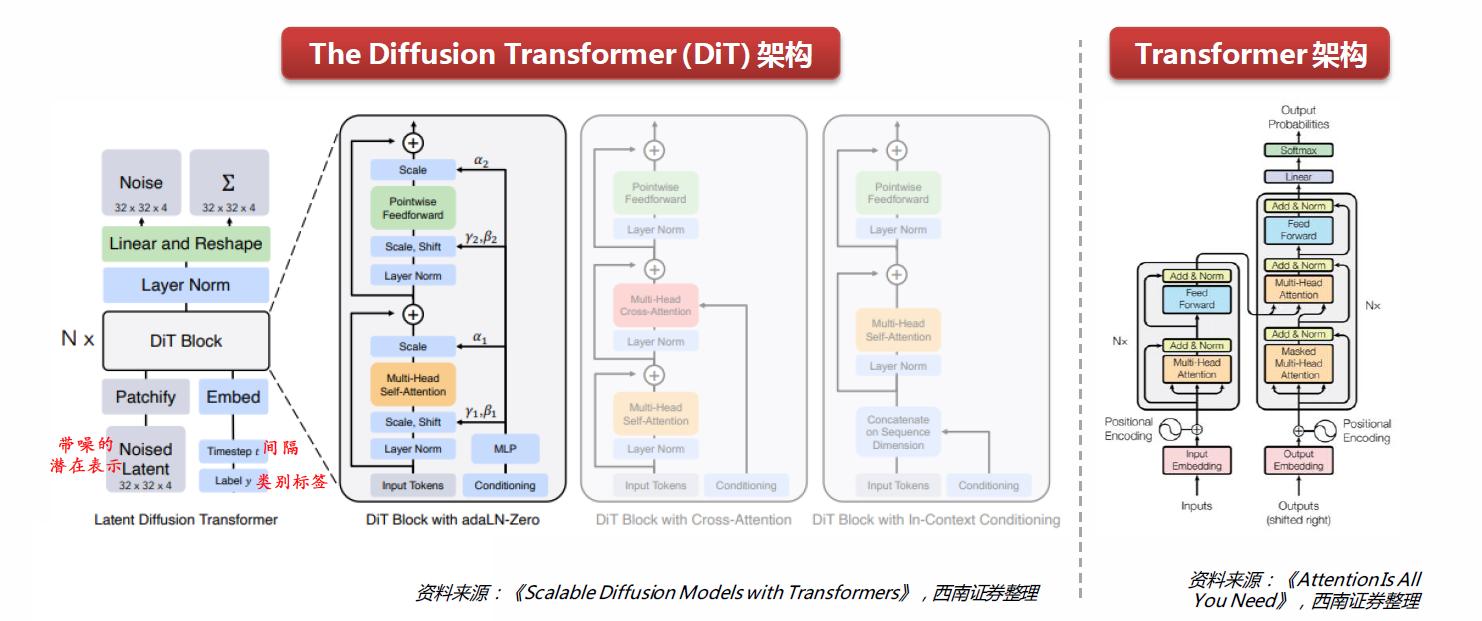
Figure 3. DiT 구조: 이미지 → patch → Transformer → noise prediction
Figure 3과 같이 DiT는 이미지를 patch 단위로 분할한 뒤,
Transformer를 통해 전역 정보를 학습합니다.
4.3 Self-Attention
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V\]이 구조 덕분에
- 이미지 전체 정보를 동시에 고려할 수 있으며
- 장거리 의존성을 효과적으로 학습할 수 있습니다
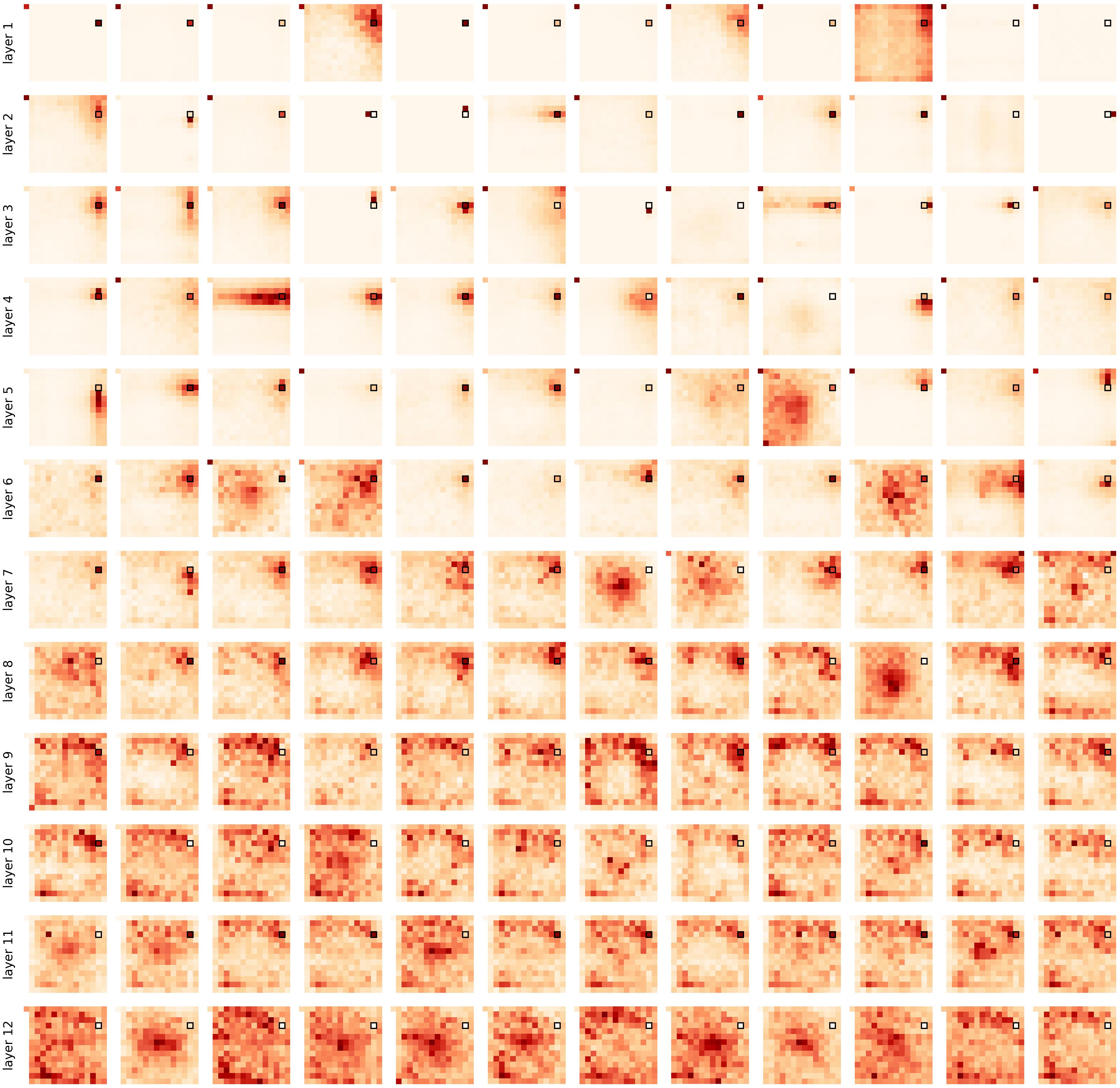
Figure 4. Self-attention을 통해 patch 간 관계를 학습하는 방식
Figure 4와 같이 self-attention은 각 patch 간의 관계를 가중치 형태로 학습합니다.
4.4 왜 Transformer인가?
기존 CNN과 비교하면 다음과 같습니다.
- CNN → 지역 정보에 강함
- Transformer → 전체 구조 이해에 강함
특히,
- 모델을 크게 확장할수록 성능이 잘 증가하며
- text conditioning과의 궁합이 좋습니다
5. DiT vs U-Net
| 항목 | U-Net | DiT |
|---|---|---|
| 구조 | CNN | Transformer |
| 정보 처리 | local | global |
| 확장성 | 제한적 | 우수 |
| 계산 비용 | 비교적 낮음 | 높음 |
6. 전체 흐름 정리
Diffusion 모델의 핵심 구조는 다음과 같습니다.
\[x_t = \sqrt{\bar\alpha_t} x_0 + \sqrt{1-\bar\alpha_t}\epsilon\]모델은 다음을 학습합니다.
\[\epsilon_\theta(x_t, t)\]구성 요소 정리
- DDPM: 기본 diffusion 구조 + stochastic sampling
- DDIM: 같은 모델, 더 빠른 sampling
- DiT: Transformer 기반 noise predictor
즉,
- DDPM → 어떻게 학습하고 생성할 것인가
- DDIM → 어떻게 빠르게 생성할 것인가
- DiT → 어떤 모델로 학습할 것인가
7. 개인 정리 (Insight)
DiT를 공부하면서 다음과 같은 점이 중요하다고 느꼈습니다.
1. diffusion은 구조적으로 단순합니다
- 결국 noise를 맞추는 문제입니다
- 하지만 매우 강력한 생성 모델입니다
2. 핵심은 함수 근사입니다
\[\epsilon_\theta(x_t, t)\]이 함수가 얼마나 복잡한 분포를 잘 근사하는지가 중요합니다.
3. Transformer는 이 문제에 잘 맞습니다
- global dependency
- scaling 성능
- 조건부 생성과의 궁합
즉 DiT의 핵심은
diffusion 구조의 변화가 아니라 함수 클래스의 변화입니다.
8. 마무리
DiT는 diffusion model의 새로운 이론이라기보다는,
기존 구조 위에서 Transformer를 적용한 모델입니다.
하지만 이 변화는 단순한 구조 변경을 넘어,
- 성능 향상
- 확장성 증가
- 새로운 연구 방향
을 제시했다는 점에서 의미가 있습니다.
Reference
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models
- Song, J., Meng, C., & Ermon, S. (2021). Denoising Diffusion Implicit Models
- Rombach, R. et al. (2022). Latent Diffusion Models
- Peebles, W., & Xie, S. (2023). Scalable Diffusion Models with Transformers
댓글남기기