One-Class Classification
이 포스팅은 One-Class Classification(OCC) 를 공부하며 정리한 글입니다.
1. One-Class Classification(OCC)이 무엇인가?
One-Class Classification(OCC)는 쉽게 말하면 정상 데이터만 보고 정상의 영역을 학습한 뒤, 그 영역 밖의 데이터를 이상치로 판단하는 방법입니다.
일반적인 이진분류 문제에서는 두 클래스가 주어집니다.
\[y \in \{0, 1\}\]예를 들어 정상 거래와 사기 거래가 모두 충분히 존재하고, 모델은 두 클래스를 구분하는 경계를 학습합니다. 그런데 현실의 이상탐지 문제에서는 비정상 데이터가 거의 없는 경우가 많고, 아예 없는 경우도 존재합니다.
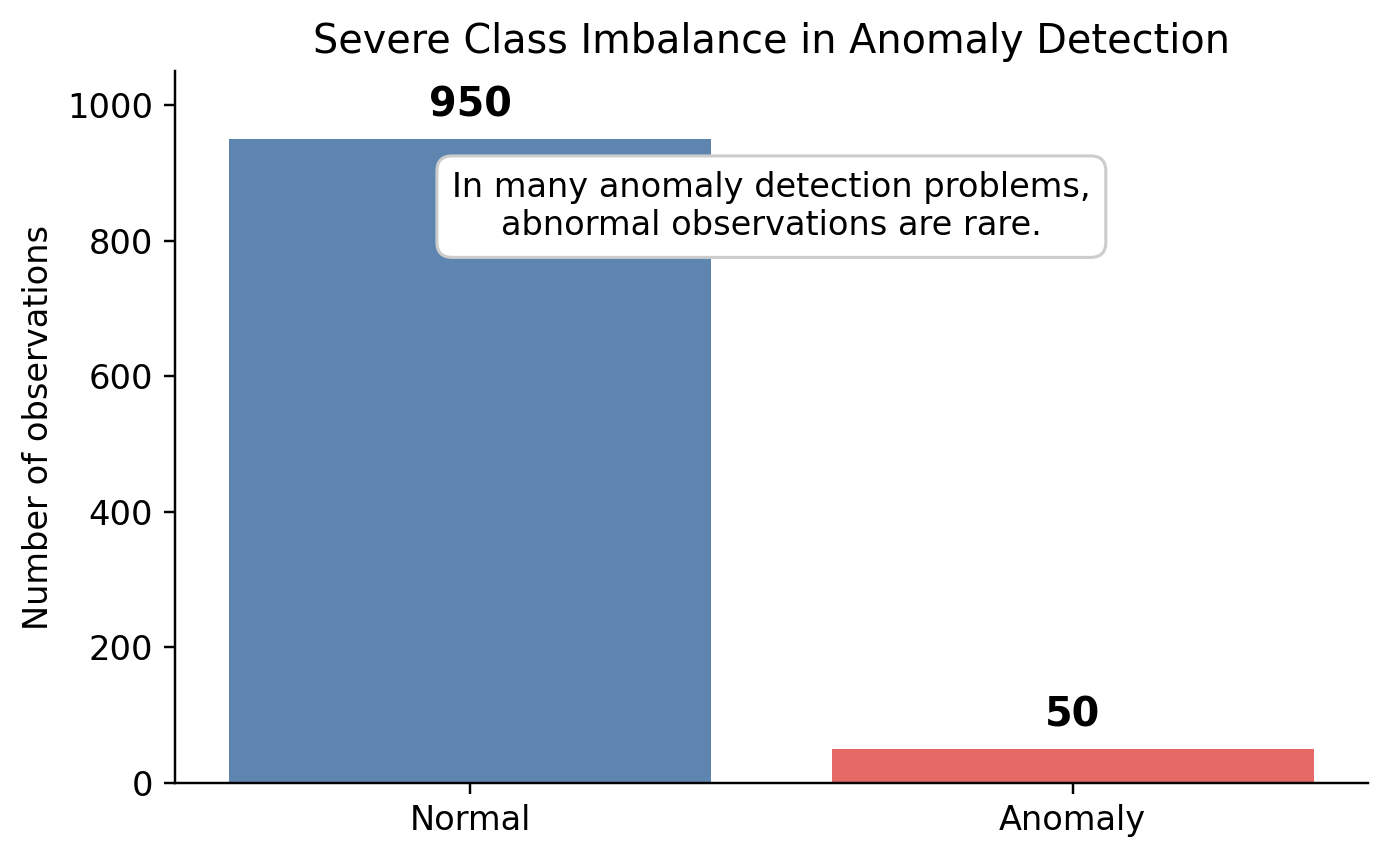
이런 상황에서는 일반적인 이진분류 모델을 사용하기 어렵습니다. 왜냐하면 모델이 비정상 Class의 패턴을 충분하게 학습하기 어렵기 때문입니다.
물론 데이터 불균형을 완화하기 위한 방법론들이 존재하긴 합니다. 예를 들어 소수 클래스를 더 중요하게 학습하도록 손실 함수에 더 큰 가중치를 주는 class weighting, 소수 클래스를 늘리는 oversampling, 다수 클래스를 줄이는 undersampling, 또는 오분류 비용을 다르게 설정하는 방법 등이 있습니다.
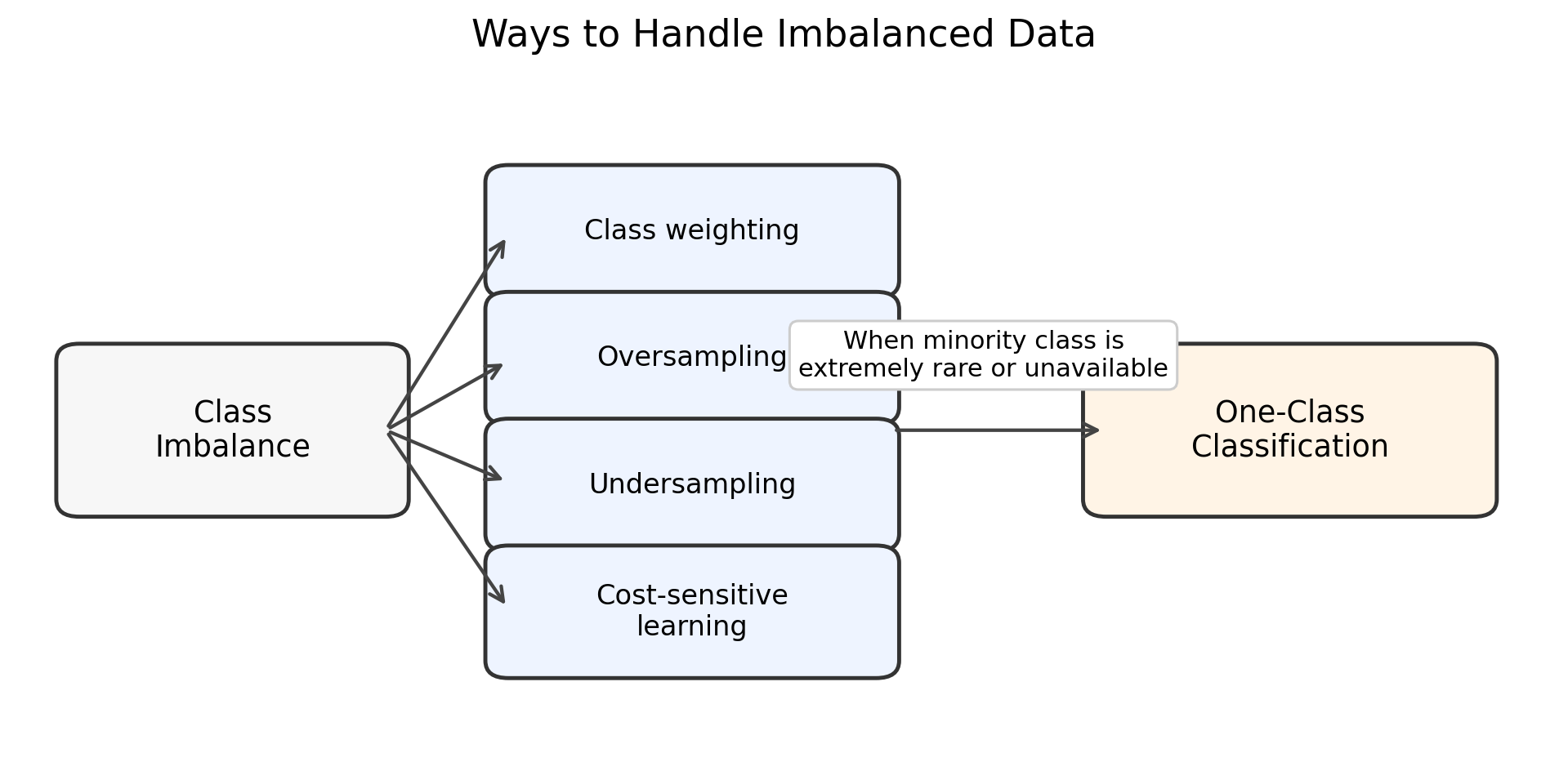
하지만 이러한 방법들은 기본적으로 정상 데이터와 이상 데이터가 모두 어느 정도 관측되어 있다는 전제를 가집니다. 반면 One-Class Classification은 이상 데이터가 매우 적거나, 아예 충분히 확보되지 않은 상황에서 정상 데이터의 분포 또는 영역을 먼저 학습한다는 점에서 차이가 있다고 볼 수 있습니다.
그래서 OCC는 질문을 바꿉니다.
일반적인 이진 분류가 다음과 같은 문제를 푼다면 \(\text{이 데이터는 정상인가, 비정상인가?}\)
OCC는 다음과 같습니다. \(\text{이 데이터는 정상 데이터의 영역안에 있는가?}\)
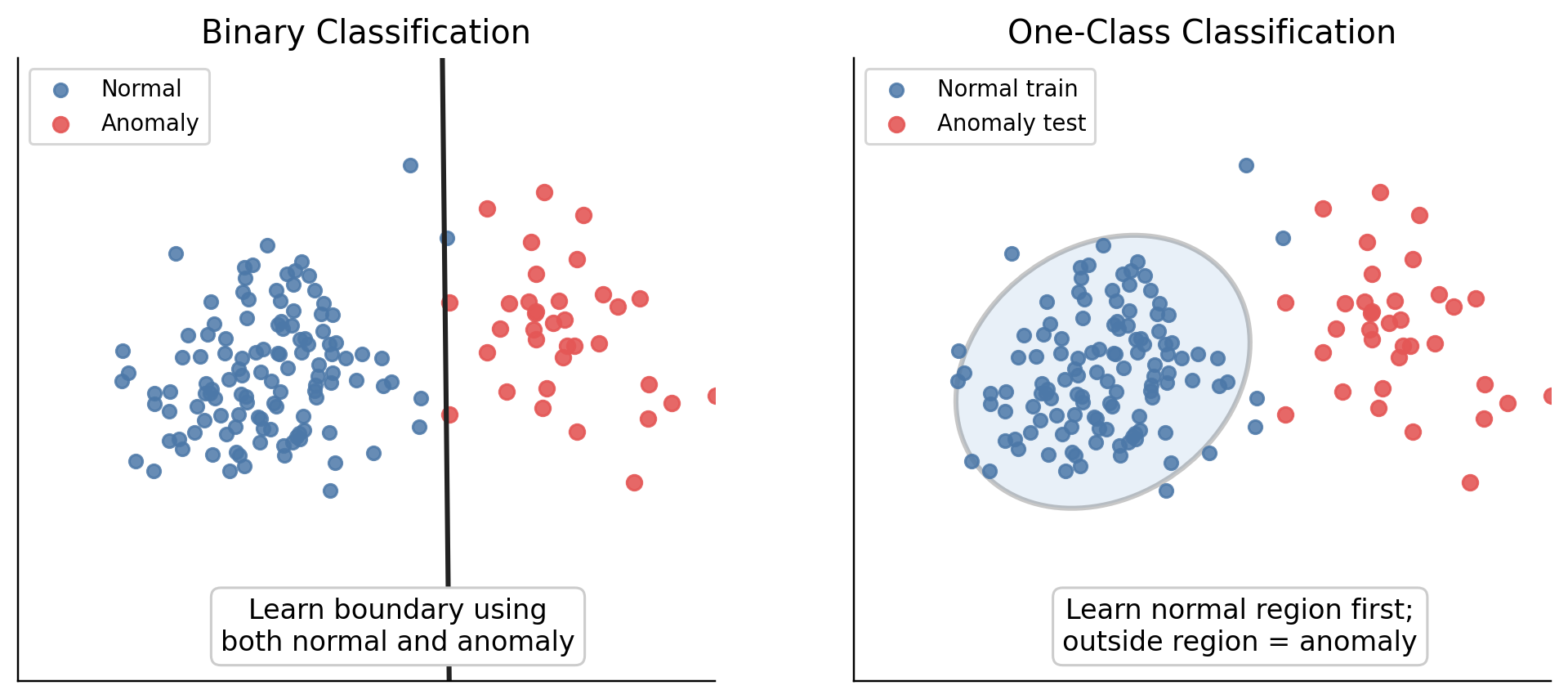
즉, OCC의 핵심은 비정상 Class를 직접 학습하는 것이 아니라, 정상 Class가 차지하는 영역을 학습함으로써, 여집합의 개념으로 비정상을 탐지하는 것입니다.
이 글에서는 OCC의 대표적인 방법론으로 OC-SVM과 SVDD를 다루어 보겠습니다.
2. SVM(Support Vector Machine) 이란?
OC-SVM을 이해하기 위해선 먼저 SVM을 알아야 합니다.
SVM은 기본적으로 이진 분류 모델입니다.
데이터가 다음과 같이 주어진다고 가정해보겠습니다.
\[(x_1, y_1),(x_2,y_2), \dots, (x_n,y_n)\]여기서 입력 데이터는
\[x_i \in \mathbb R^p\]이고 라벨은
\[y_i \in \{-1,1\}\]입니다.
SVM의 목표는 두 Class를 나누는 경계를 찾는 것입니다. 이 경계는 다음과 같은 Hyperplane으로 표현됩니다.
\[w^\top x + b = 0\]여기서 $w$는 경계의 방향을 결정하는 벡터이고, $b$는 Bias입니다.
새로운 데이터 $x^*$가 들어왔을 때,
\[w^\top x^* + b > 0\]이면 Class가 1
\[w^\top x^* + b < 0\]이면 Class를 -1로 분류합니다.
즉 Decision Function은 다음과 같이 쓸 수 있습니다.
\[f(x^*) = sign(w^\top x^* + b)\]3. SVM의 핵심은 Margin
SVM은 Margin이 가장 큰 경계를 찾습니다.
margin은, 분류 경계와 가장 가까운 데이터 사이의 거리로 정의합니다. SVM은 두 클래스를 나누는 여러 경계 중에서 가장 안정적인 경계를 고르려고 합니다.
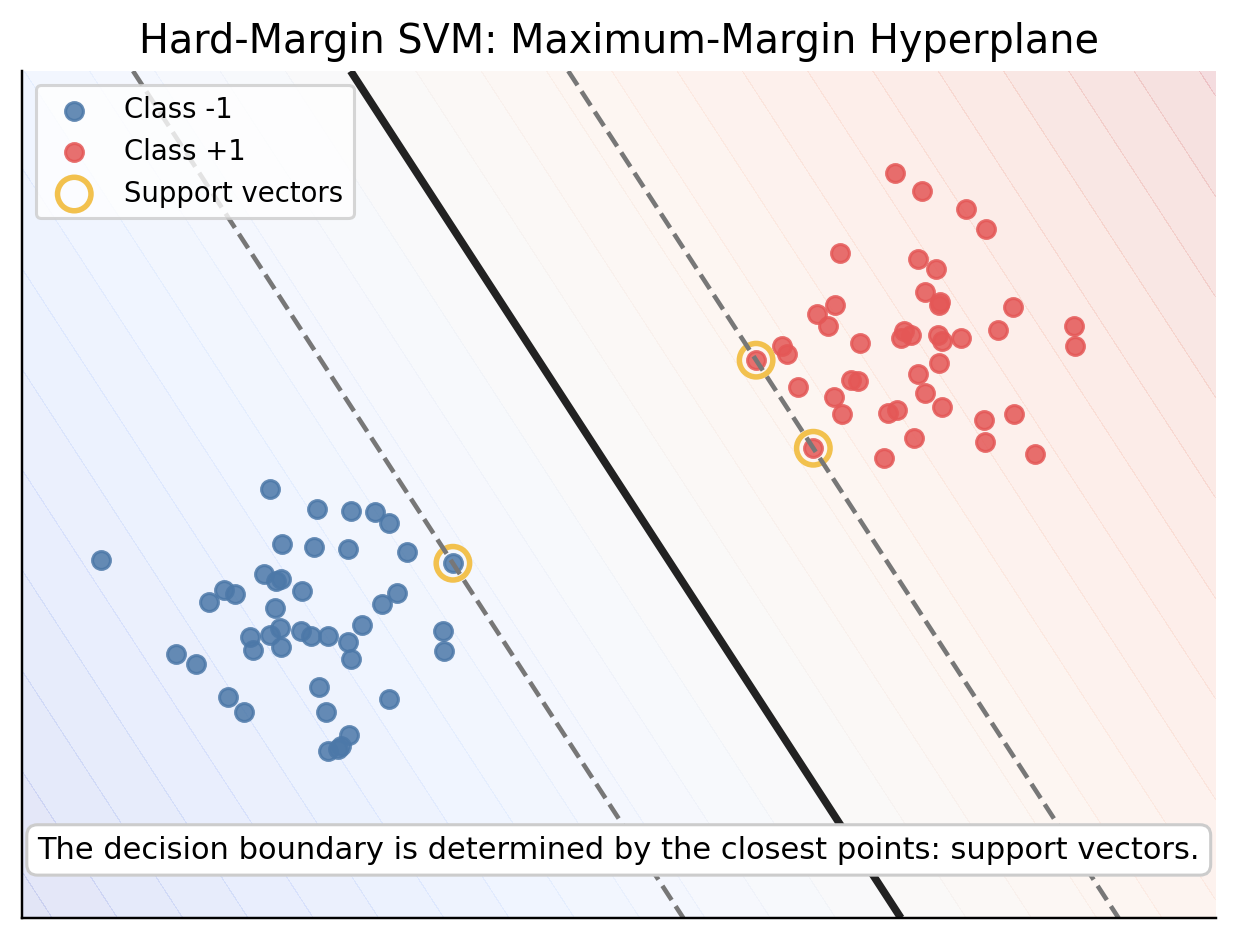
직관적으로 보면 다음과 같이 생각해볼 수 있습니다.
| 경계가 데이터에 너무 가까우면, 새로운 데이터가 조금만 흔들려도 오분류될 가능성이 크다. 그러니 Class 사이에 최대한 넓은 여백을 주는 경계를 찾아보자. |
이 때 분류 경계에 가장 가까이 있는 점들이 중요하며, 이 점들을 Support Vector라고 부릅니다. 즉, support vector들이 분류 경계를 결정하는 모델입니다.
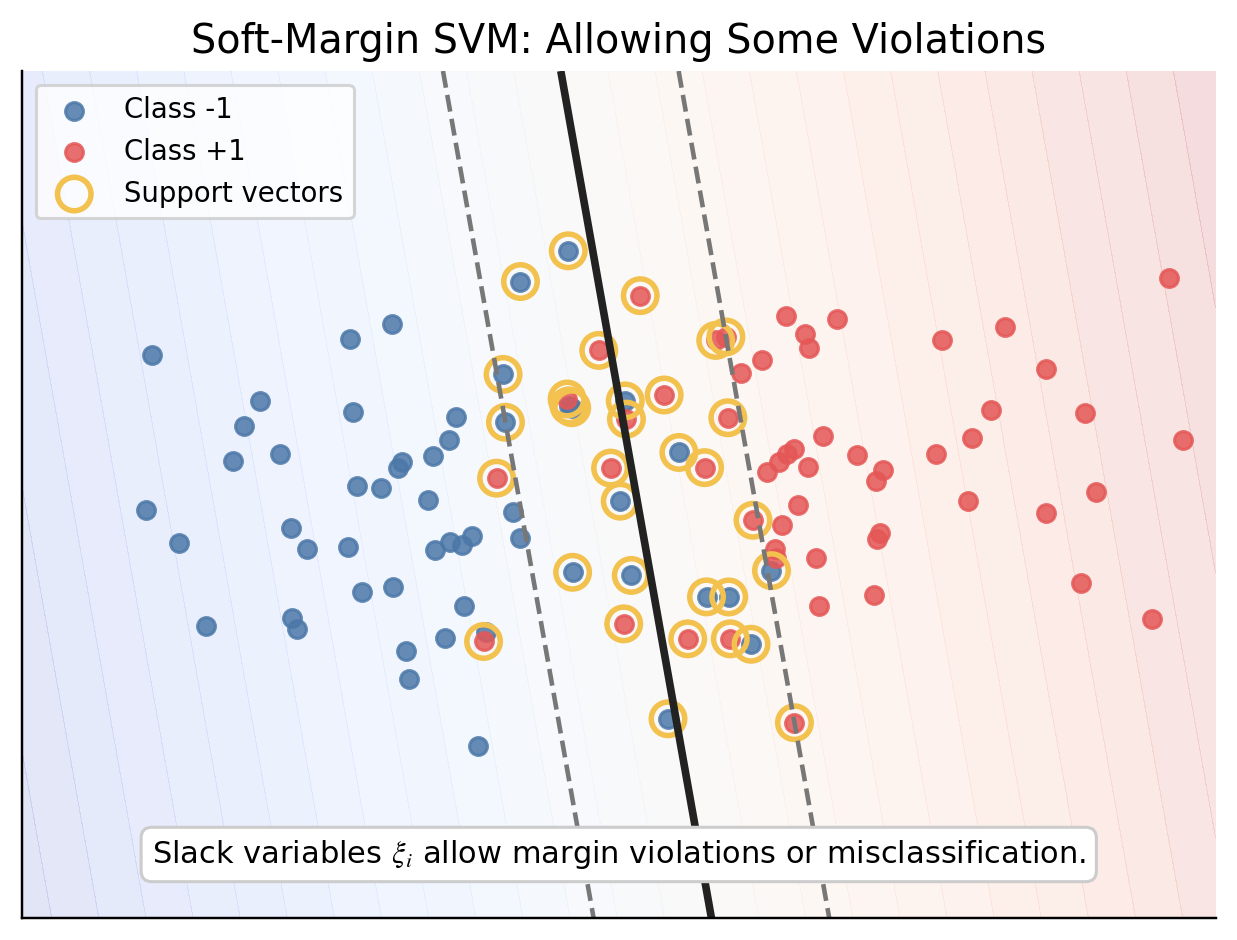
4. Soft-Margin SVM
현실의 데이터는 완벽하게 나눠지지 않는 경우가 더 많습니다. 그래서 SVM은 어느 정도의 오분류를 허용합니다. 이때 사용하는 변수가 slack variable $\xi_i$ 입니다.
SVM의 soft-margin objective는 다음과 같습니다.
\(\min_{w,b,\xi}\dfrac{1}{2} ||w||^2 +C \sum_{i=1}^n \xi_i\) subject to \(y_i(w^\top \phi(x_i) + b) \geq 1- \xi_i, \quad \xi_i \geq 0\)
| 이 objective에서 첫 번째 항 $\dfrac{1}{2} | w | ^2$ 은 Margin을 크게 만들기 위한 항이고 두 번째 항 $C\sum_{i=1}^n\xi_i$ 은 오분류나 margin을 침범한 경우에 대한 penalty입니다. |
$C$는 두 항의 비율을 조절하는 하이퍼 파라미터입니다. $C$가 크면 오분류에 대한 패널티를 키워서 학습 데이터를 더 강하게 적합하려고 하고, 작아지면 오분류를 어느정도 허용하여 margin을 더 넓게 만들 수 있습니다.
5. Kernel Trick
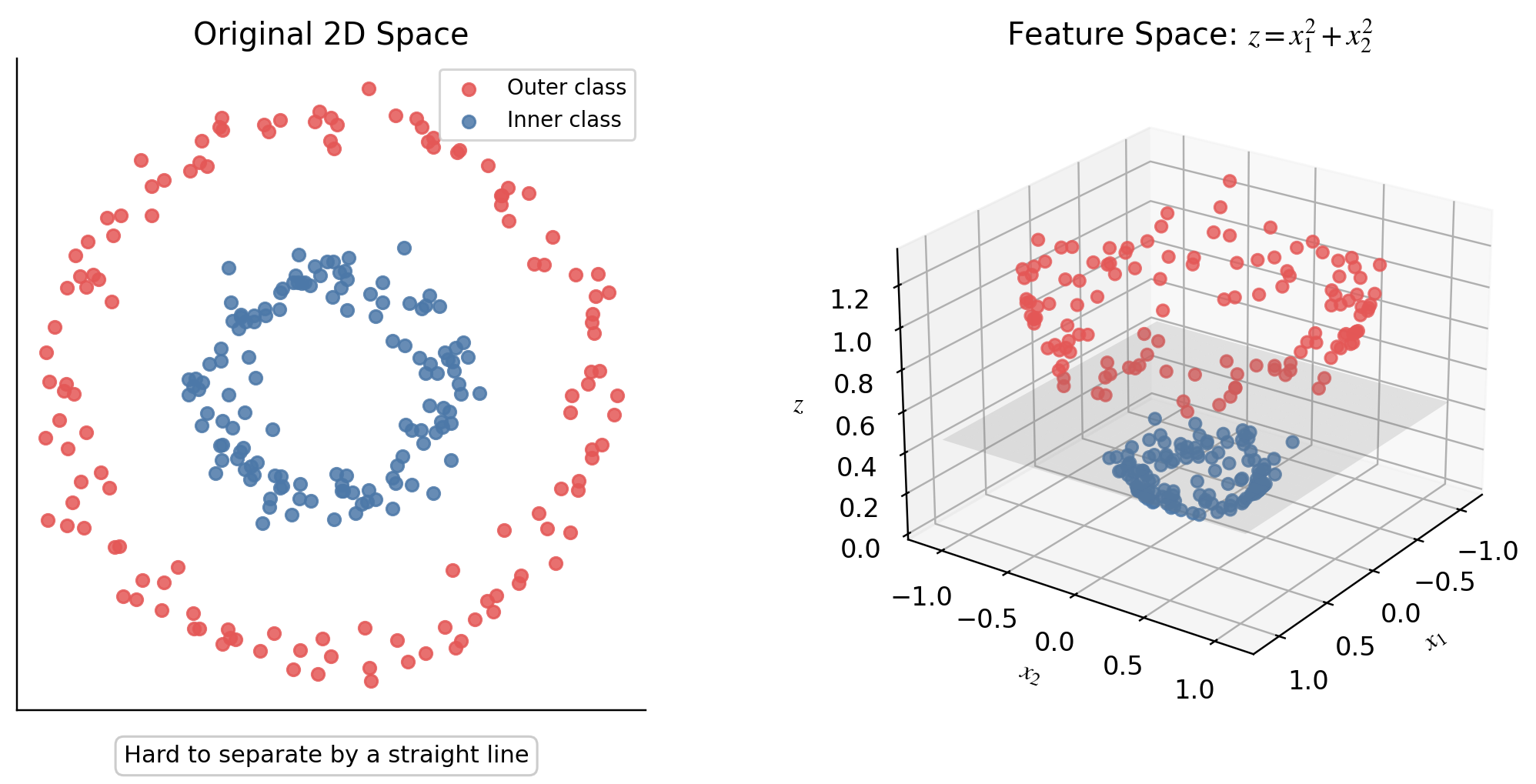
SVM이 강력한 이유 중 하나는 Kernel Trick에 있습니다.
어떤 데이터는 원래 공간에서는 선형적으로 나누기 어렵습니다. 예를 들어 2차원 평면에서는 직선 하나로 클래스를 나누기 어려울 수 있습니다.
이때 데이터를 더 높은 차원의 공간으로 보냅니다.
\[x \rightarrow \phi(x)\]그러면 기존의 공간에서는 복잡하게 섞여 있던 데이터가 고차원 공간에서는 선형적으로 분리될 수 있습니다. 하지만 $\phi(x)$를 직접 계산하면 비용이 너무 클 수 있습니다.
그래서 SVM은 $\phi(x)$를 직접 계산하지 않고, 두 점 사이의 내적만 커널 함수를 통해 계산합니다.
\[k(x_i, x_j) = \phi(x_i)^\top \phi(x_j)\]이게 kernel trick입니다.
SVM의 classification function은 다음과 같이 표현됩니다.
\(f(x) = \sum_{i=1}^n\alpha_iy_i k(x_i,x) + b\) 여기서 $k(x_i,x)$가 kernel function이고, $\alpha_i$는 각 학습 샘플의 중요도를 나타내는 계수입니다.
6. One-Class SVM
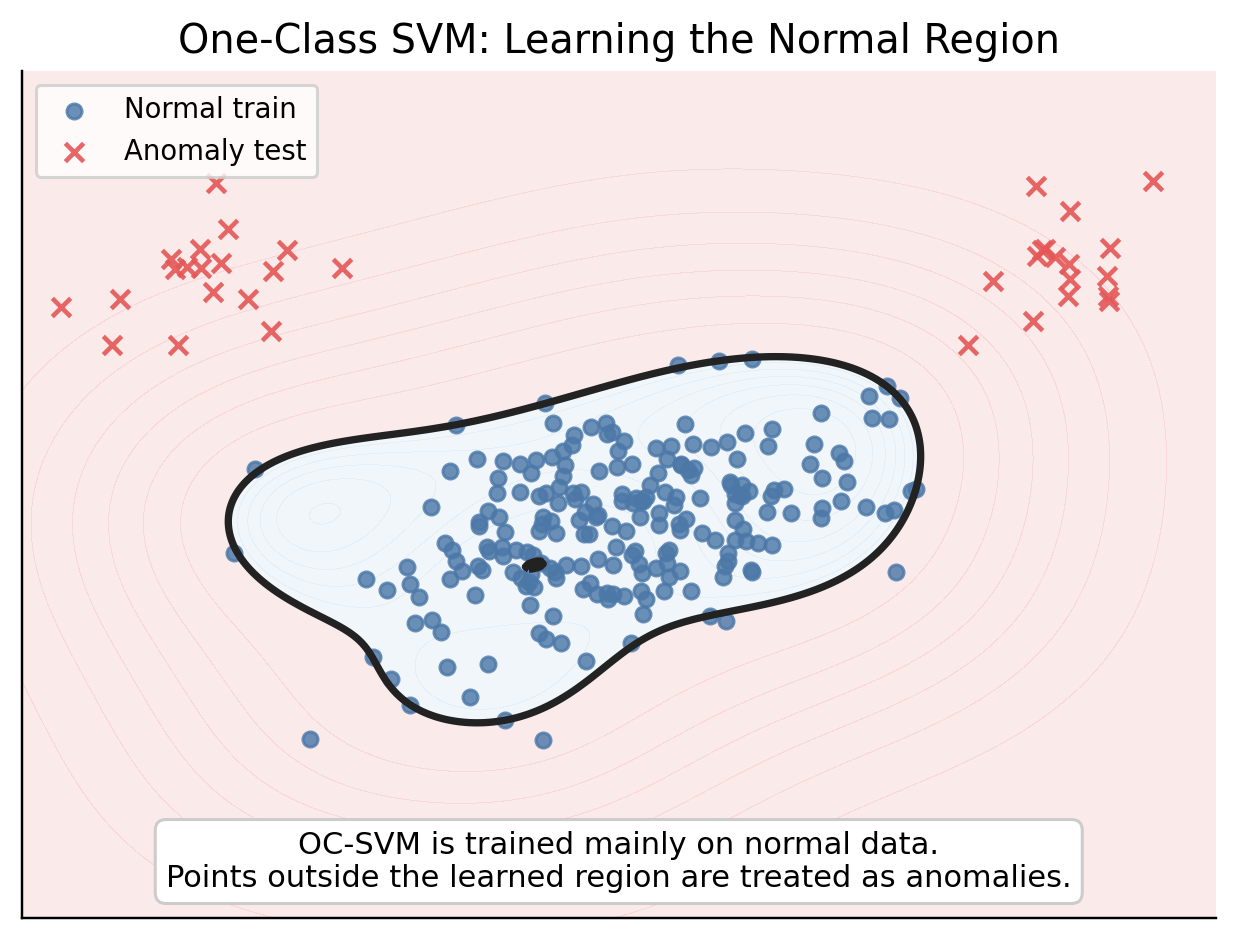
OC-SVM은 일반 SVM을 one-class problem에 맞게 바꾼 모델입니다. 일반 SVM은 두 class를 나눕니다. 하지만 OC-SVM은 주로 정상 데이터만 가지고 학습을 진행합니다. 목표는 다음과 같습니다.
\[\text{정상 데이터가 존재하는 영역을 학습한다.}\]그리고 새로운 데이터가 그 영역 밖에 존재한다면 anomaly로 판단한다.
OC-SVM의 핵심 아이디어는 정상 데이터와 원점(origin)을 분리하는 Hyperplane을 찾는 것이다.
OC-SVM의 Hyperplane은 다음과 같이 쓸 수 있습니다.
\[w^\top\phi(x) - \rho = 0\]여기서 $\rho$는 threshold 역할을 합니다.
새로운 데이터 $x^*$에 대해서
\[w^\top\phi(x^*) - \rho \geq 0\]이면 정상
\[w^\top\phi(x^*) - \rho \leq 0\]이면 anomaly로 분류하는 것입니다.
7. OC-SVM의 목적함수
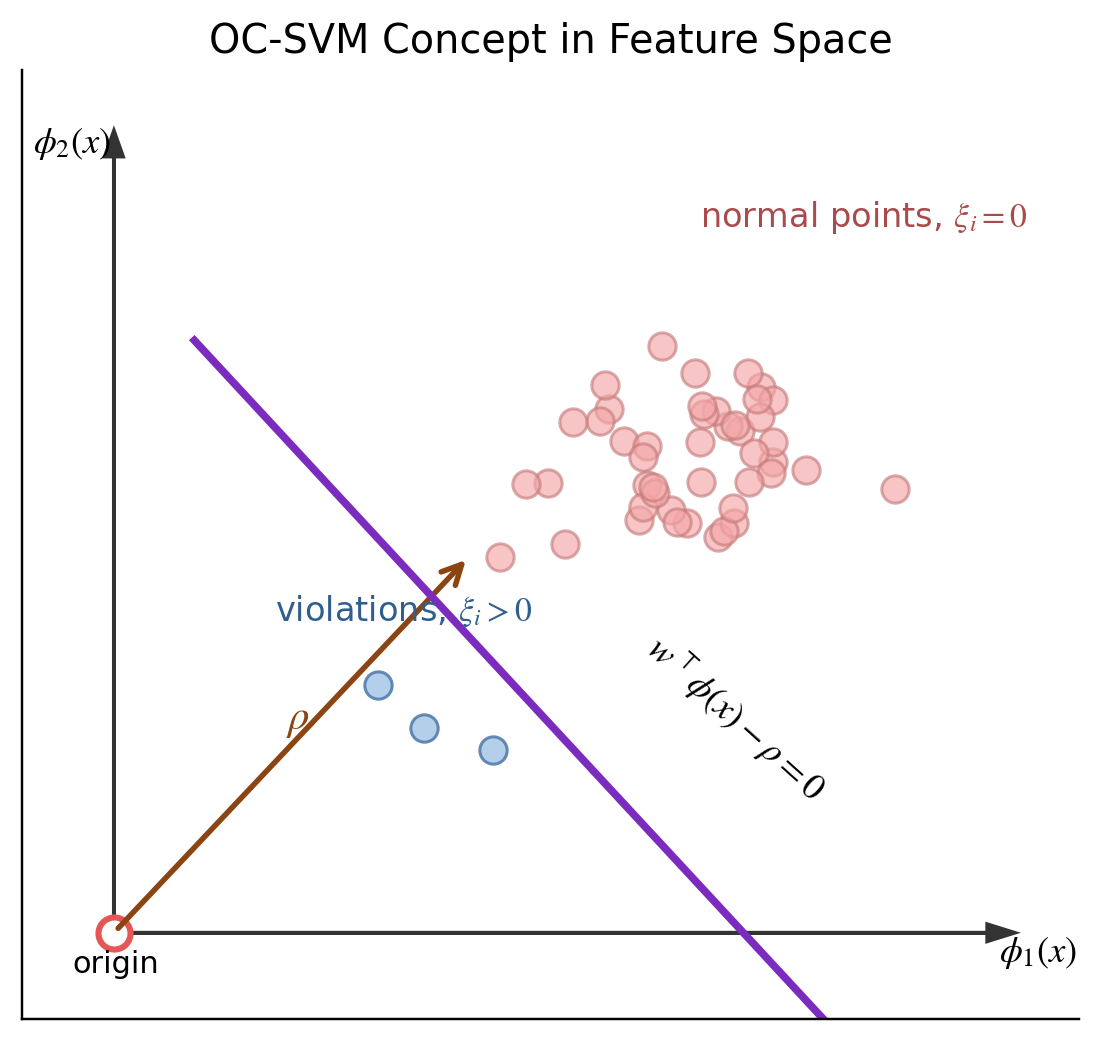
OC-SVM의 최적화 문제는 다음과 같습니다. \(\min_{w,\rho,\xi} \dfrac{1}{2}||w||^2 + \dfrac{1}{\nu n}\sum_{i=1}^n \xi_i -\rho\) subject to
\[w^\top\phi(x_i)\geq \rho - \xi_i,\quad \xi_i \geq 0\]이 식을 하나씩 뜯어보면 다음과 같습니다.
첫 번째 항은 margin을 조절하고, 두 번째 항은 boundary를 위반한 데이터에 대한 penalty로 해석할 수 있습니다. 마지막 세 번째 항은 $\rho$를 크게 하도록 유도합니다.
즉 OC-SVM은 정상 데이터들을 origin으로부터 잘 분리하면서, 동시에 너무 많은 데이터를 boundary 밖으로 보내지 않도록 학습하게 됩니다.
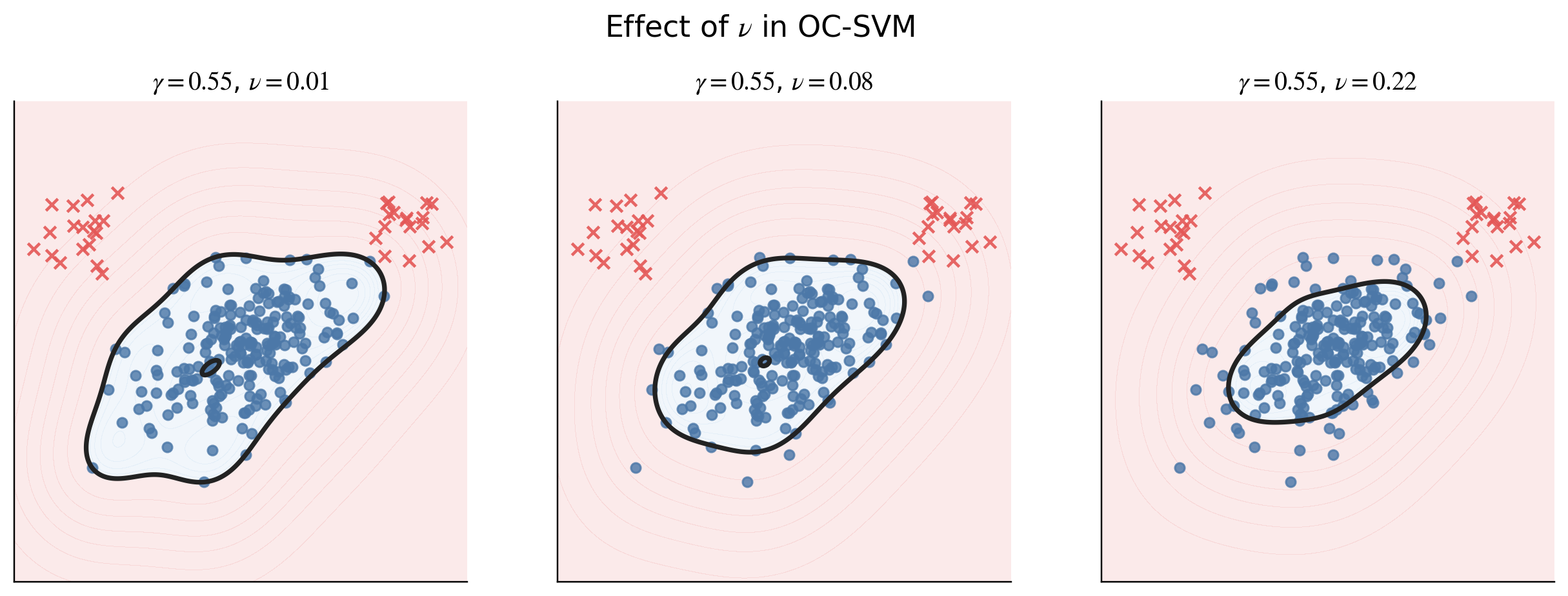
8. $\nu$ 는 무엇인가
OC-SVM에서 $\nu$는 매우 중요한 파라미터입니다. $\nu$는 두 가지 의미를 가집니다.
- Outlier 비율의 upper bound 역할
- Support Vector 비율의 lower bound 역할
쉽게 말하면 $\nu$는 모델에게 이런 식으로 말하는 것입니다.
| 정상 데이터 중 일부는 boundary 밖에 있어도 괜찮아. 그 허용 정도를 $\nu$로 하자! |
$\nu$가 작으면 두 번째 항이 커지게 되고, 그래서 대부분의 데이터를 정상 영역안에 포함시키려고 합니다. 그래서 결과적으로 정상 영역이 넓어지게 됩니다.
반대로 $\nu$가 크면 패널티가 작아져, 일부 데이터를 boundary 밖으로 보내는 것을 허용하게 되고, 결과적으로 boundary가 더 빡빡해지게 됩니다.
9. OC-SVM의 Decision function
OC-SVM의 학습이 끝나면 새로운 데이터 $x^*$에 대해서 다음 값을 계산합니다.
\[f(x^*) = sign\bigg(\sum_{i=1}^n\alpha_i^* k(x_i, x^*)-\rho^*\bigg)\]여기서 $\alpha_i^, \rho^$는 학습된 계수 값이고 $k$는 커널 함수입니다.
이 결과가 1이면 정상, -1이면 비정상으로 판단하는 것입니다.
즉, OC-SVM은 새로운 데이터가 support vector들과 얼마나 비슷한 지를 보고, 그 값이 threshold $\rho^*$보다 충분히 큰 지 확인합니다.
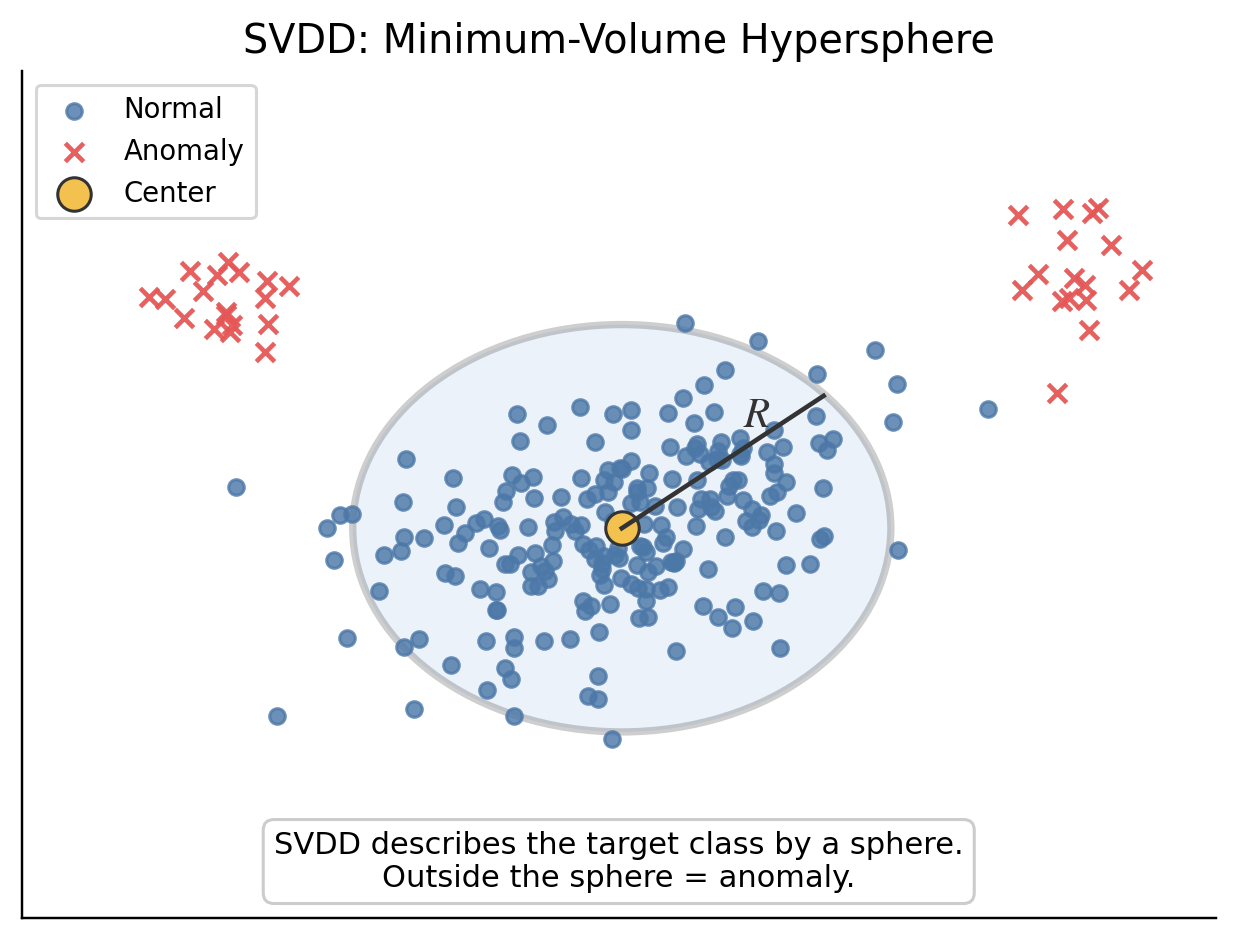
10. SVDD 란?
SVDD는 Support Vector Data Description의 약자입니다.
OC-SVM이 정상 데이터와 origin을 분리하는 Hyperplane을 찾는 방법이라면, SVDD는 정상 데이터를 감싸는 가장 작은 Hypersphere를 찾는 방법이라고 할 수 있습니다.
즉, OC-SVM의 개념은 다음과 같습니다.
\[\text{정상 데이터 vs Origin}\]반면 SVDD는
\[\text{정상 데이터를 감싸는 최소의 초구}\]SVDD의 목표는 Hypersphere의 중심 $a$와 반지름 $R$을 찾는 것입니다.
\(\min_{R,a,\xi} R^2 + C\sum_{i=1}^n \xi_i\) subject to \(||\phi(x_i) - a||^2 \leq R^2 + \xi_i,\quad \xi_i \geq 0\)
정상 데이터는 이 sphere 내부에 있어야 합니다.
그래서 새로운 데이터가 들어오면
\[||\phi(x^*) - a||^2 \leq R^2\]이면 정상, 그렇지 않으면 비정상으로 분류합니다.
11. Deep SVDD 란?
마지막으로 Deep SVDD라는 SVDD에 deep learning을 결합한 방법을 간략히 살펴보겠습니다.
기존 SVDD에서는 Feature mapping을 커널 트릭 $\phi(x)$를 사용하여 표현합니다.
하지만 Deep SVDD는 이 feature mapping을 neural network로 바꿉니다.
\[\phi(x;W)\]여기서 $W$는 신경망의 가중치입니다.
즉, Deep SVDD는 raw input을 신경망에 넣어서 representation을 만들고, 그 representation들이 하나의 중심 근처에 모이도록 학습을 진행합니다.
objective는 다음과 같습니다.
\[\min_W\dfrac{1}{n}\sum_{i=1}^n||\phi(x_i;W)||^2 + \dfrac{\lambda}{2}\sum_{h=1}^H ||W_h||^2\]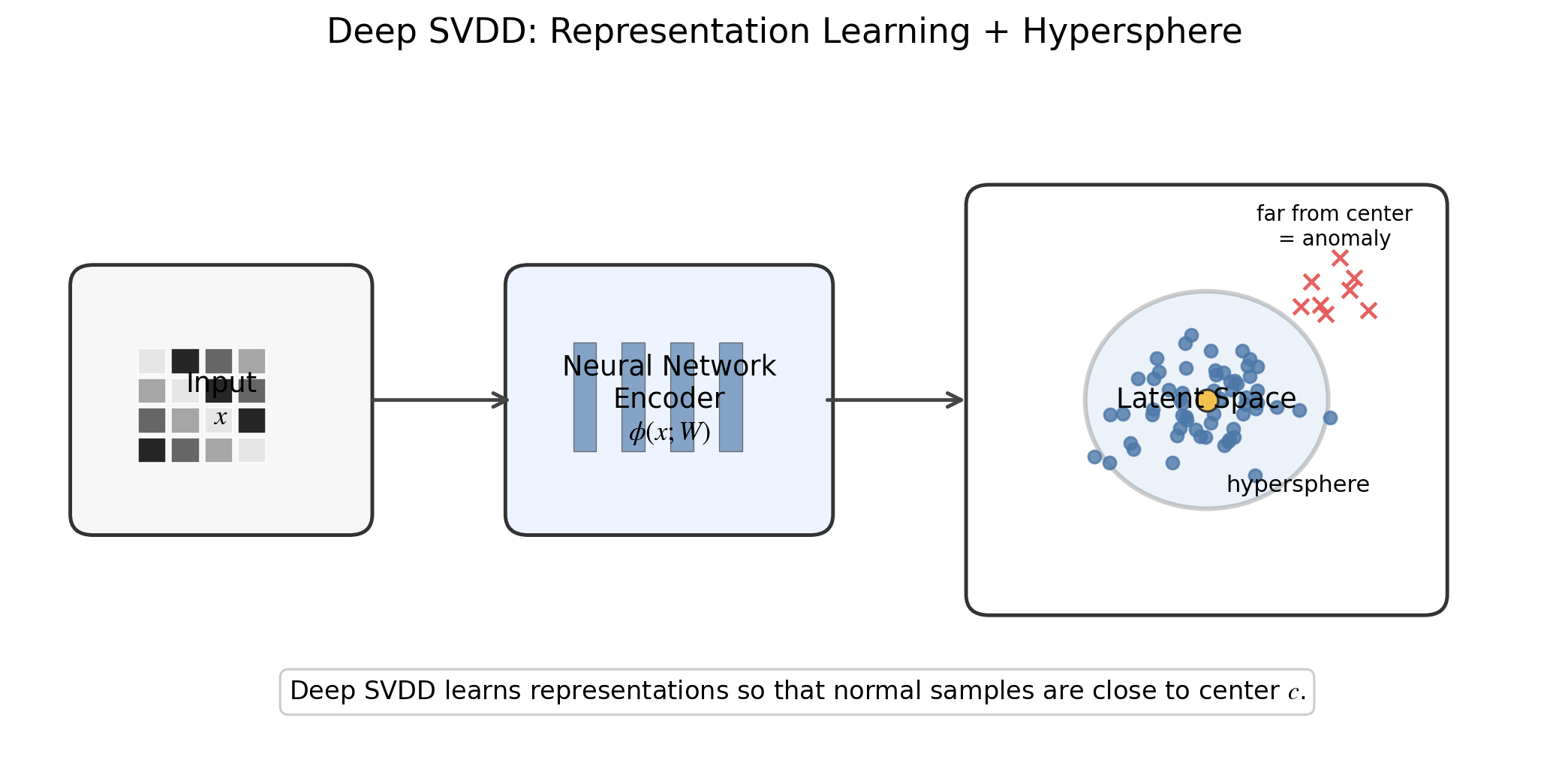
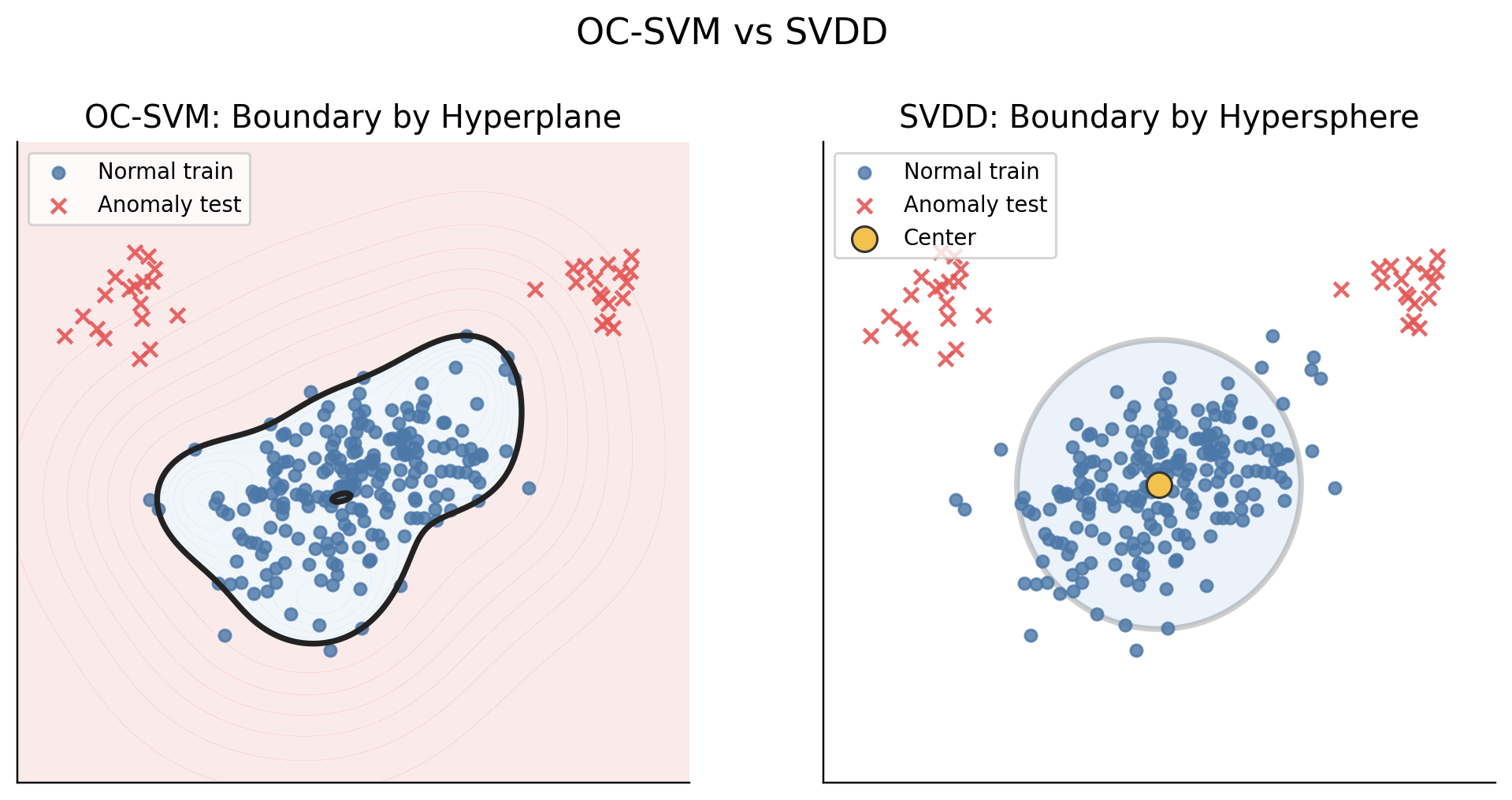
12. OC-SVM vs SVDD
OC-SVM과 SVDD는 둘다 OCC 방법론이지만, 정상 영역을 정의하는 방식이 다릅니다.
| 모델 | 핵심 아이디어 | 기하학적 관점 | 이상치 판단 |
|---|---|---|---|
| OC-SVM | 정상 데이터와 origin을 분리 | Hyperplane | 경계의 바깥이면 이상치로 분류 |
| SVDD | 정상 데이터를 sphere로 감쌈 | Hypersphere | Hypersphere의 바깥이면 이상치로 분류 |
| Deep SVDD | neural network representation을 Hypersphere 안에 모음 | learned feature space + hypersphere | 중심에서 멀면 이상치로 분류 |
Conclusion
오늘은 One-Class Classification의 개념과 대표적인 방법론인 OC-SVM, SVDD, Deep SVDD에 대해 정리해보았습니다.
일반적인 이진분류는 정상 데이터와 비정상 데이터가 모두 어느 정도 존재한다는 전제에서 두 클래스를 나누는 경계를 학습합니다. 반면 OCC는 비정상 데이터가 매우 적거나 충분하지 않은 상황에서 정상 데이터가 차지하는 영역을 먼저 학습하고, 그 영역의 바깥을 비정상으로 판단합니다.
SVM은 두 클래스를 나누는 여러 경계 중 margin이 가장 큰 경계를 찾는 모델입니다. OC-SVM은 이 아이디어를 one-class setting으로 확장하여, feature space에서 정상 데이터와 origin을 분리하는 경계를 학습합니다. 이때 $\nu$는 허용할 outlier의 비율과 support vector의 비율에 영향을 주기 때문에, 정상 영역을 얼마나 넓게 또는 빡빡하게 잡을지를 결정하는 중요한 하이퍼파라미터입니다.
SVDD는 OC-SVM과는 조금 다른 관점에서 정상 데이터를 설명합니다. OC-SVM이 hyperplane을 이용해 정상 영역을 구분한다면, SVDD는 정상 데이터를 감싸는 최소 크기의 hypersphere를 찾습니다. Deep SVDD는 여기에 neural network를 결합하여, 원본 데이터가 아니라 신경망이 학습한 representation space에서 정상 데이터를 하나의 중심 근처에 모으는 방식입니다.
결국 OCC의 핵심은 “비정상을 직접 학습한다”기보다는 “정상이 무엇인지 먼저 정의한다”는 데 있습니다. 따라서 이상 데이터의 수가 매우 적은 문제, 새로운 유형의 이상이 계속 등장하는 문제, 또는 비정상 패턴을 사전에 충분히 수집하기 어려운 문제에서 유용하게 사용할 수 있습니다. 다만 정상과 이상이 많이 겹치는 경우, 정상 데이터 자체가 매우 다양하게 분포하는 경우, 또는 하이퍼파라미터를 부적절하게 선택하는 경우에는 성능이 크게 달라질 수 있습니다. 실제 적용에서는 데이터의 특성, 이상 탐지의 목적, false positive와 false negative의 비용을 함께 고려해야 합니다.
References
- Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20, 273–297.
- Boser, B. E., Guyon, I. M., & Vapnik, V. N. (1992). A training algorithm for optimal margin classifiers. Proceedings of the Fifth Annual Workshop on Computational Learning Theory, 144–152.
- Schölkopf, B., Platt, J. C., Shawe-Taylor, J., Smola, A. J., & Williamson, R. C. (2001). Estimating the support of a high-dimensional distribution. Neural Computation, 13(7), 1443–1471.
- Tax, D. M. J., & Duin, R. P. W. (2004). Support Vector Data Description. Machine Learning, 54, 45–66.
- Ruff, L., Vandermeulen, R., Görnitz, N., Deecke, L., Siddiqui, S. A., Binder, A., Müller, E., & Kloft, M. (2018). Deep One-Class Classification. Proceedings of the 35th International Conference on Machine Learning, PMLR 80, 4393–4402.
- Perera, P., Oza, P., & Patel, V. M. (2021). One-Class Classification: A Survey. arXiv:2101.03064.
- He, H., & Garcia, E. A. (2009). Learning from Imbalanced Data. IEEE Transactions on Knowledge and Data Engineering, 21(9), 1263–1284.
- Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research, 16, 321–357.
댓글남기기