베이지안 딥커널 머신을 이용한 양식 넙치 성장 예측
프로젝트 요약
- 개요: 양식 넙치 성장량을 예측하기 위해 ANN 표현 학습과 Gaussian Process 기반 베이지안 커널 회귀를 결합한 연구
- 기간: 2024.12-2025.08
- 데이터: 완도 2개 양식장, 제주 3개 양식장, 총 7개 수조의 수온, 용존산소, 사료량, 월별 체중 데이터
- 기술 스택: Bayesian Deep Kernel Machine Regression, Gaussian Process, ANN, Heteroscedastic Modeling, LOOCV
- 성과(성능): BDKMR 기준 MAE 0.1895, MSE 0.0629로 비교 모델 중 최저 오차 달성
문제 정의
국내 양식 넙치(olive flounder)의 성장 예측을 위해, 가우시안 프로세스 회귀와 신경망 기반 표현 학습을 결합한 Bayesian Deep Kernel Machine Regression (BDKMR) 모델을 제안한 연구입니다. 완도 2개 양식장과 제주 3개 양식장, 총 7개 수조에서 2023년 3월부터 2024년 7월까지 수집한 종단 데이터를 바탕으로 수온, 용존산소, 개체당 사료량이 성장에 미치는 비선형 관계를 모델링했습니다.
접근 방법
아키텍처 요약
데이터 정렬, 신경망 기반 특징 학습, 베이지안 커널 회귀를 한 흐름으로 정리했습니다.
1. Aquaculture Data
- 완도 2개, 제주 3개 양식장
- 총 7개 수조, 2023.03-2024.07
- 수온, 용존산소, 개체당 사료량, 초기 로그 체중
2. Feature Learning
측정 주기가 다른 센서 데이터와 월별 체중 데이터를 동일한 성장 구간으로 정렬한 뒤, ANN 기반 feature map으로 비선형 구조를 학습합니다.
3. Bayesian Kernel Layer
Gaussian process 기반 BDKMR로 예측과 불확실성을 함께 추정하고, 관측별 정밀도를 반영하기 위해 이분산 구조 Var(y_i)=sigma^2/n_i 를 사용합니다.
반응 변수
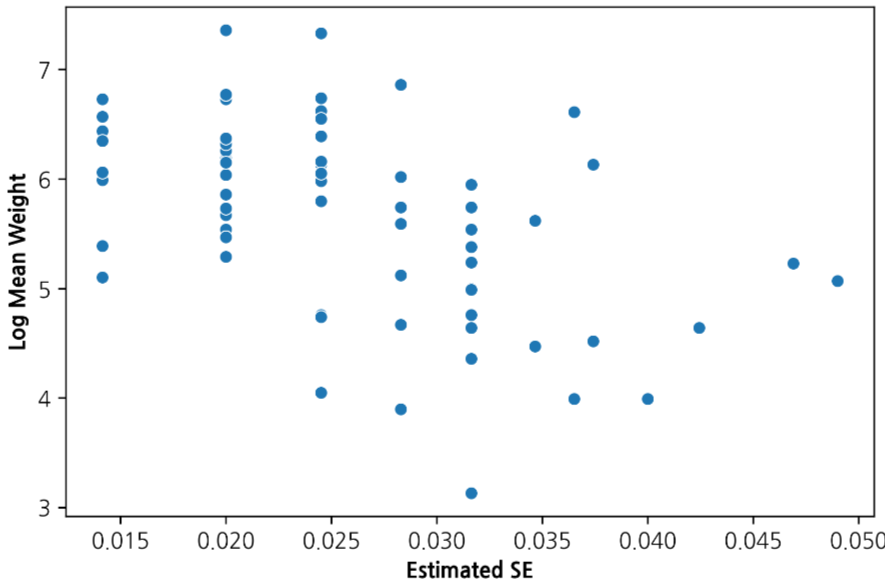
농가별 무작위 50마리 표본에서 계산한 월별 로그 평균 체중
추론 방식
MAP estimation과 Laplace approximation을 사용해 계산 가능성과 베이지안 구조를 동시에 확보
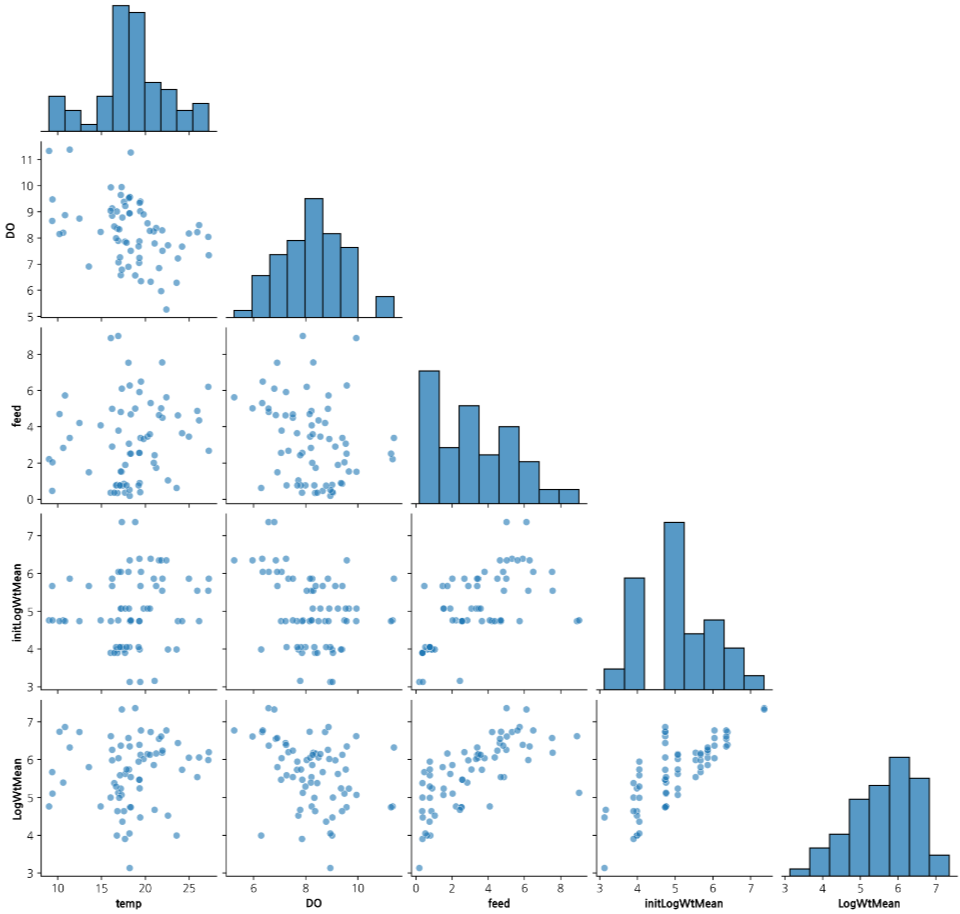
EDA 및 성능 비교
탐색적 데이터 분석(EDA)을 통해 변수 구조를 먼저 확인하고, 이후 논문에 보고된 LOOCV 성능을 비교했습니다.
MAE
MSE
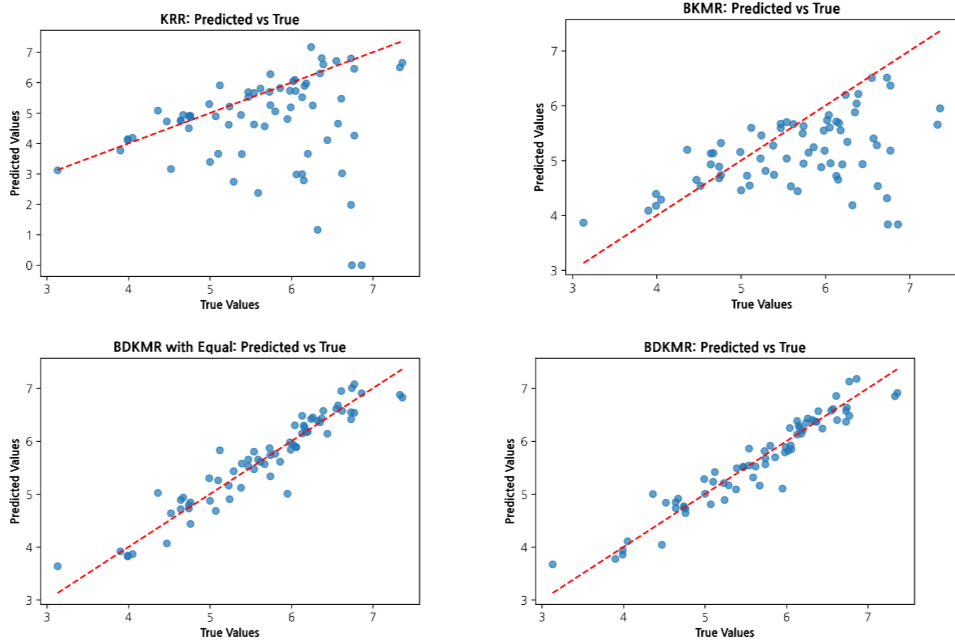
BDKMR은 BKMR 대비 MAE를 약 72.8%, MSE를 약 93.3% 줄였습니다.
접근 방법 세부
- 수온과 용존산소는 1분 단위 센서 데이터, 사료량은 일 단위 기록, 체중은 월 단위 측정으로 수집되었으며, 이를 동일한 성장 관측 구간에 맞춰 정렬해 분석용 데이터셋을 구성했습니다.
- 월별 체중 측정에서는 농가별로 무작위 50마리를 표본 추출해 로그 평균 체중을 반응변수로 사용했고, 개체 수와 측정 변동성을 반영하기 위해 \(Var(y_i) = \sigma^2 / n_i\) 형태의 이분산 구조를 적용했습니다.
- BKMR의 불확실성 정량화 장점과 ANN의 표현 학습 능력을 결합한 BDKMR을 설계해, 환경 변수 간 복잡한 비선형 상호작용을 더 유연하게 학습하도록 구성했습니다.
- 추론은 MAP 추정과 Laplace approximation을 기반으로 수행해 베이지안 구조를 유지하면서도 실제 예측 문제에 적용 가능한 계산 효율을 확보했습니다.
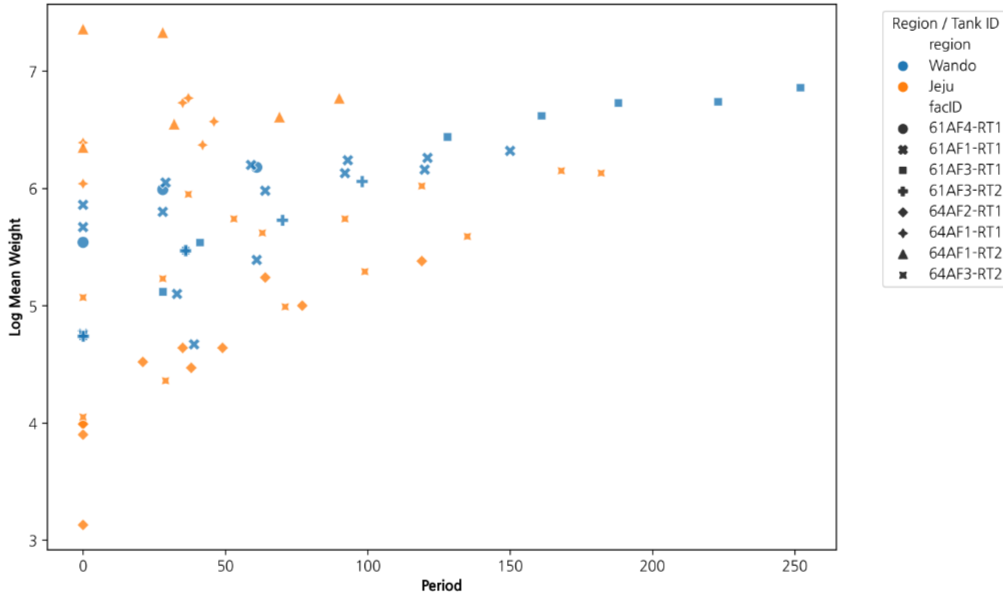
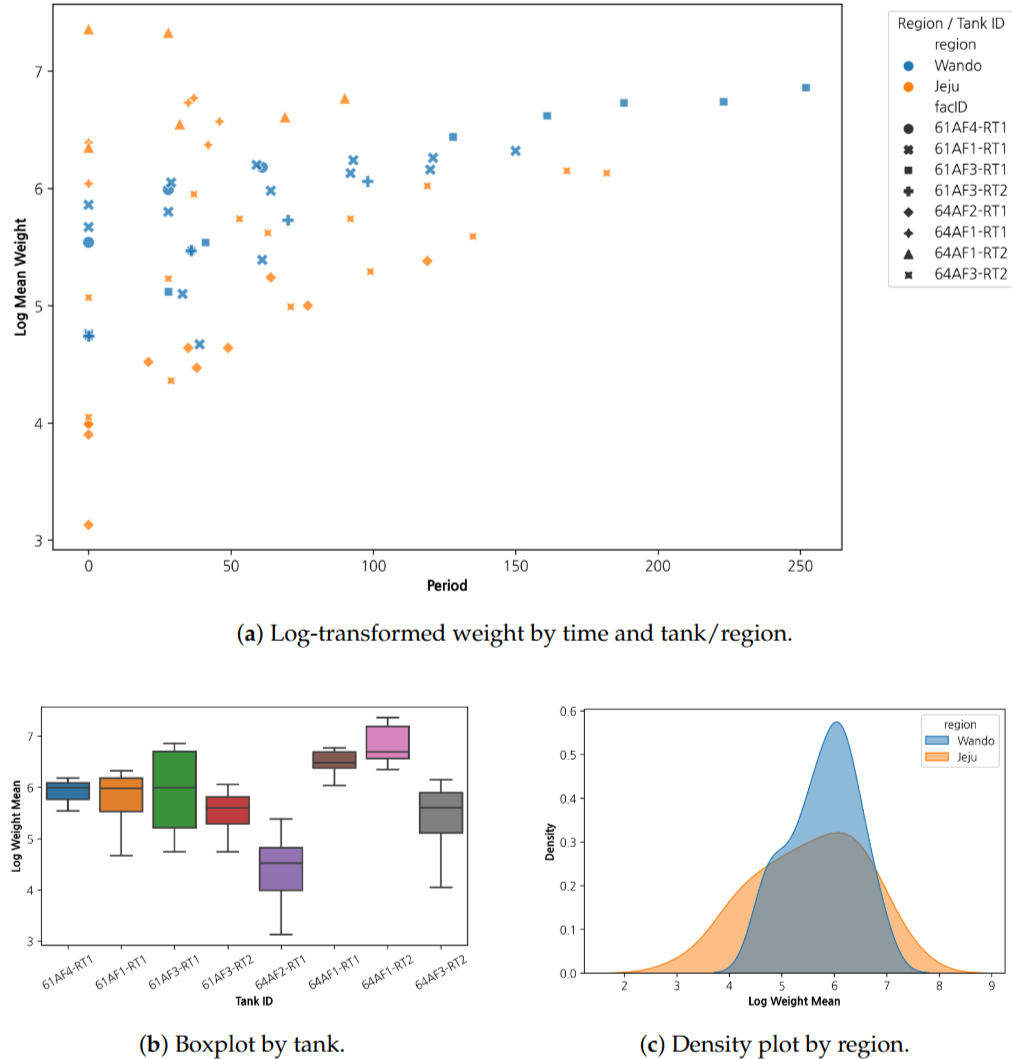
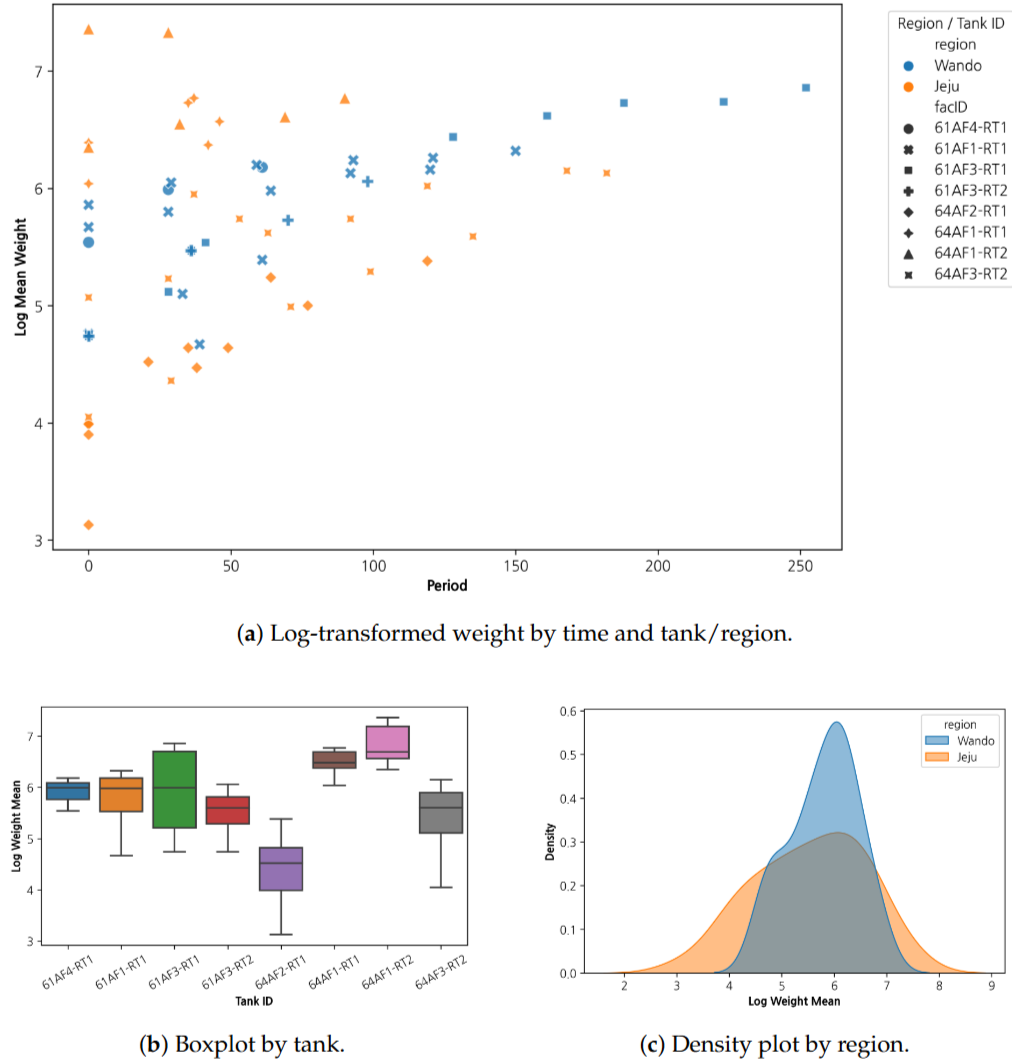
데이터와 EDA
EDA에서는 먼저 양식장, 수조, 시간에 따른 성장 곡선이 같은 형태로 움직이는지 확인했습니다. 체중은 전반적으로 증가하지만 수조별 분포와 지역별 밀도는 동일하지 않았고, 환경 변수와 초기 체중 사이에도 단순 선형 관계로 보기 어려운 패턴이 나타났습니다. 이 때문에 고정된 커널 하나보다 ANN feature map을 거친 딥커널 구조를 사용하는 방향으로 모델링을 정했습니다.
- 대상 데이터: 완도 2개 양식장, 제주 3개 양식장, 총 7개 수조
- 수집 기간: 2023년 3월부터 2024년 7월까지
- 입력 변수: 수온, 용존산소, 개체당 사료량, 초기 로그 체중
- 반응 변수: 월별 로그 평균 체중
- 비교 모델: KRR, BKMR, BDKMR(Equal), BDKMR
- 평가 지표: Leave-One-Out Cross-Validation (LOOCV), MAE, MSE
성과(성능)
- 제안한 BDKMR은
MAE 0.1895,MSE 0.0629를 기록해 비교 모델 중 가장 낮은 예측 오차를 보였습니다. - 동분산 가정의
BDKMR(Equal)보다 이분산 구조를 반영한 BDKMR이 더 우수해, 관측별 정밀도 차이를 고려하는 것이 실제 양식 데이터 예측에 중요함을 확인했습니다. - 기준 모델인 KRR은
MAE 1.1141,MSE 3.5665, BKMR은MAE 0.6977,MSE 0.9447로 나타나, 딥커널 기반 표현 학습이 기존 커널 모델 대비 뚜렷한 성능 개선을 제공했습니다.
사용 기술
- Bayesian Deep Kernel Machine Regression
- Gaussian Process Regression
- Artificial Neural Networks
- Heteroscedastic Modeling
- Leave-One-Out Cross-Validation
포트폴리오 관점의 의미
양식 데이터는 변수별 측정 주기가 다르고 환경 스트레스에 따라 변동성이 크게 달라지는 특성이 있습니다. 이 연구는 딥러닝의 표현 학습과 베이지안 커널 모델의 해석 가능성 및 불확실성 추정을 결합해, 급이 전략, 출하 시점, 환경 제어와 같은 실제 양식 운영 의사결정에 활용할 수 있는 성장 예측 프레임워크를 제시했다는 점에서 의미가 있습니다.
느낀점
이 프로젝트를 진행하면서 가장 크게 느낀 점은, 좋은 예측 모델을 만드는 일은 모델을 복잡하게 설계하는 것만으로 해결되지 않는다는 점이었습니다. 실제 양식 데이터는 측정 주기가 서로 다르고, 수조별 환경 차이와 관측 정밀도 차이도 커서, 데이터를 어떻게 정렬하고 해석하느냐가 성능에 직접적인 영향을 주었습니다.
특히 EDA를 통해 변수 간 관계가 단순 선형 구조가 아니라는 점과, 관측마다 분산 수준이 다르다는 점을 먼저 확인한 것이 이후 모델링 방향을 정하는 데 큰 도움이 되었습니다. 개인적으로는 딥러닝 기반 특징 학습과 베이지안 커널 회귀를 결합했을 때, 예측 정확도뿐 아니라 불확실성까지 함께 다룰 수 있다는 점이 가장 인상적이었고, 앞으로도 실제 데이터 문제에서는 이런 해석 가능한 확률적 접근이 중요하다고 느꼈습니다.
논문 정보
- Junhee Kim, Seung-Won Seo, Ho-Jin Jung, Hyun-Seok Jang, Han-Kyu Lim, Seongil Jo, “Predicting Flatfish Growth in Aquaculture Using Bayesian Deep Kernel Machines”, Applied Sciences, 2025.
- DOI: 10.3390/app15179487
- 원문 PDF: Applied Sciences 2025 논문 PDF 열기