서울시 미세먼지 예측
프로젝트 요약
- 개요: 2017-2018년 서울시 일평균 대기오염 데이터를 기반으로 2019년 PM10, PM2.5 농도를 1, 2, 3일 후까지 예측하는 모델 비교 프로젝트
- 기간: 2025 여름
- 데이터: Kaggle
Air Pollution in Seoul, 서울시 측정소 정보, 일별 대기오염 측정값, 기상청 일별 기온 데이터, 지하철역 근접성 변수 - 기술 스택: Python, pandas, SARIMA, SARIMAX, LightGBM, DLinear, Moran’s I, 시공간 feature engineering
- 성과(성능): 1일 후 예측 기준 SARIMAX가 PM2.5
MAE 7.15,RMSE 10.44, PM10MAE 10.92,RMSE 16.65로 가장 우수
문제 정의
이 프로젝트의 목표는 2017-2018년의 서울시 일평균 대기오염 데이터를 학습해, 2019년의 PM10과 PM2.5 농도를 1일, 2일, 3일 후까지 예측하는 것입니다. 단순히 하나의 모델을 적용하는 것이 아니라, 통계적 시계열 모델, 외생 변수를 포함한 시계열 모델, 비선형 머신러닝 모델, 딥러닝 기반 시계열 모델을 비교해 어떤 접근이 이 데이터에 가장 적합한지 확인했습니다.
미세먼지는 계절성, 기온, 인접 지역의 농도, 측정소 위치 특성이 함께 작용합니다. 따라서 모델링의 핵심은 미세먼지 자체의 시간 패턴만 보는 것이 아니라, 외부 변수와 공간적 패턴을 얼마나 잘 반영하느냐였습니다.
데이터 준비
원본 데이터는 오염물질 정보, 측정소 정보, 측정값 데이터로 나뉘어 있었고, 이를 통합한 뒤 각 측정소별 시계열 형태로 재구성했습니다. 이후 물리적으로 불가능한 음수 농도 값을 오류로 판단해 NaN으로 변환하고, 주변 정상 값을 이용한 cubic interpolation으로 보간했습니다. 보간 이후에도 음수가 발생할 수 있는 값은 최종적으로 0으로 보정했습니다.
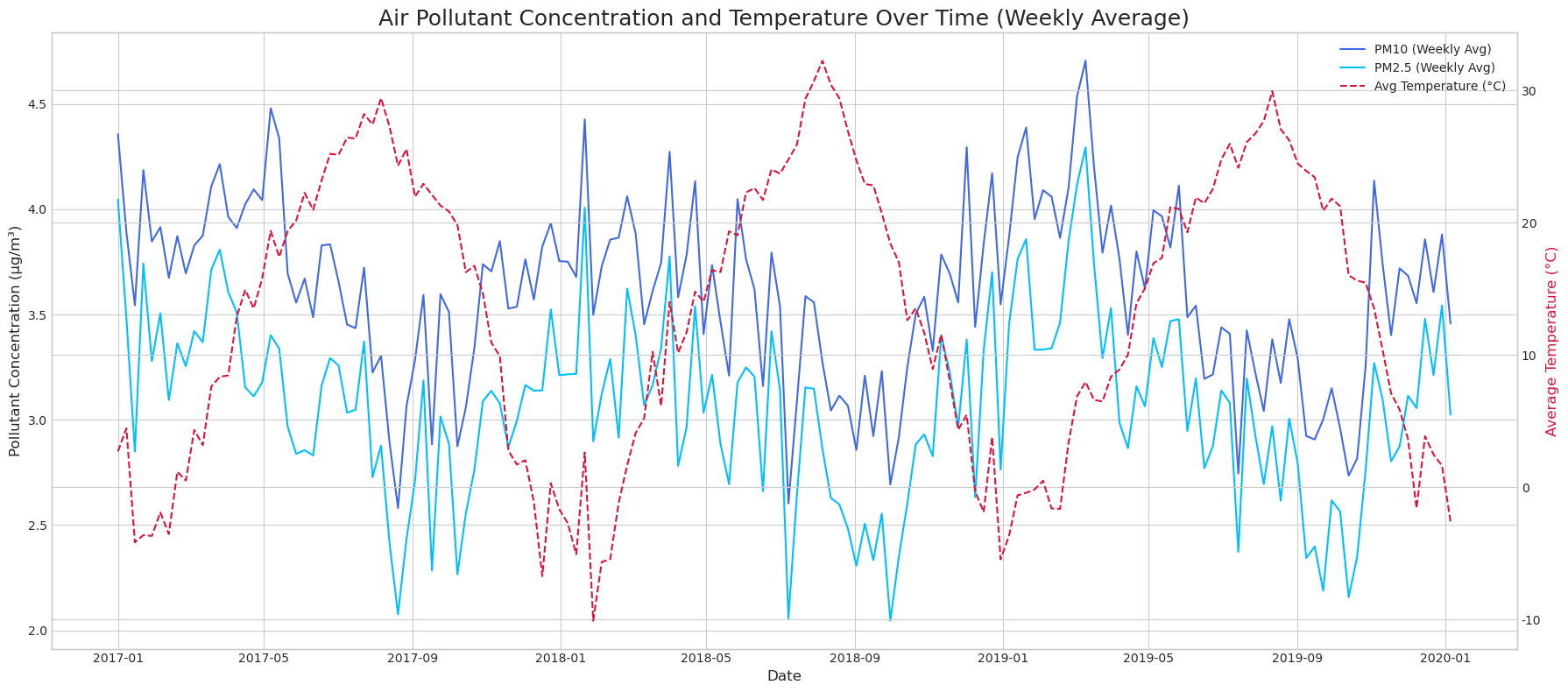
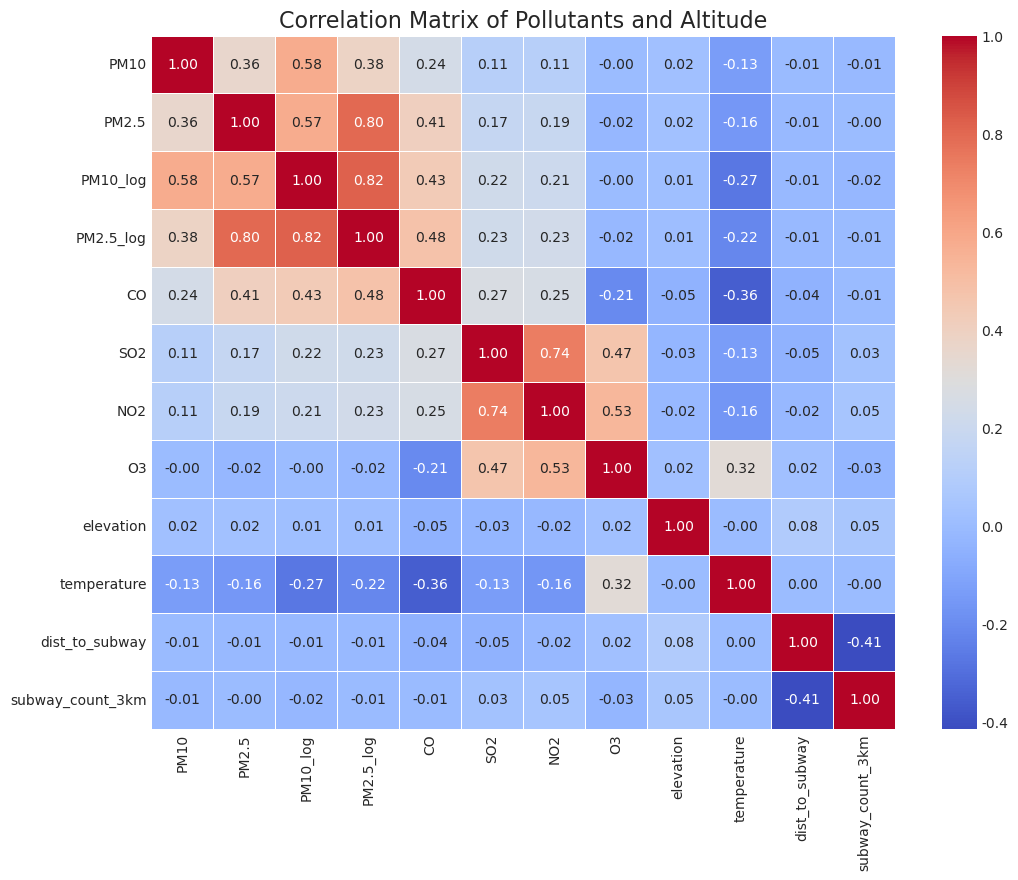
추가 변수로는 기상청 기상자료개방포털의 서울시 일별 기온 데이터를 결합했습니다. 기온이 높은 여름철에는 미세먼지 농도가 낮아지고, 기온이 낮은 겨울철에는 농도가 높아지는 음의 상관관계가 확인되어 외부 변수로 사용할 가치가 있었습니다.
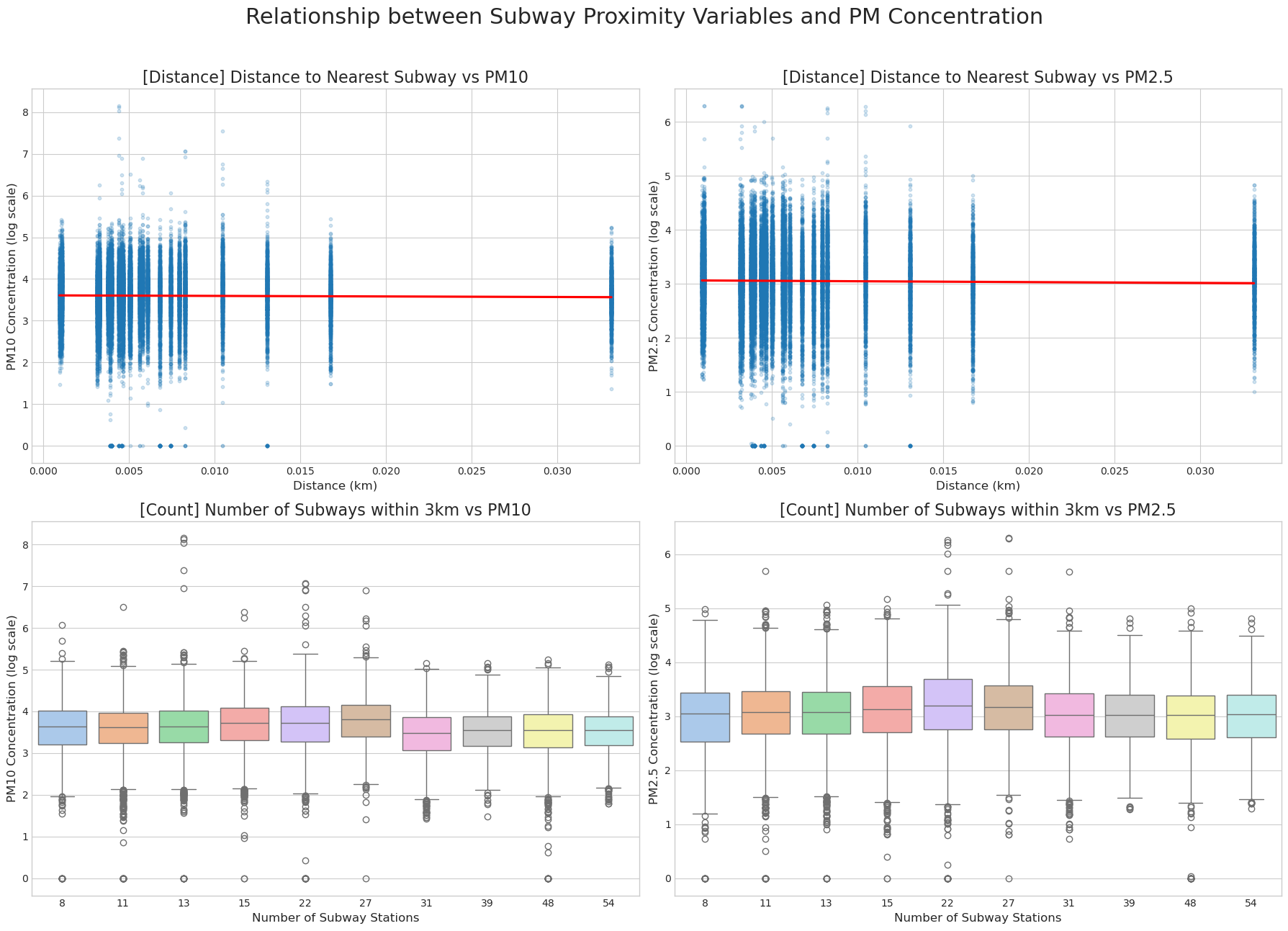
측정소 주변의 도시화 정도를 간접적으로 반영하기 위해 국가철도공단 데이터를 활용해 가장 가까운 지하철역까지의 거리, 측정소 반경 내 지하철역 개수 변수도 생성했습니다. 다만 EDA에서는 지하철 근접성 변수와 미세먼지 농도 사이의 뚜렷한 선형 패턴은 확인되지 않았습니다.
데이터와 EDA
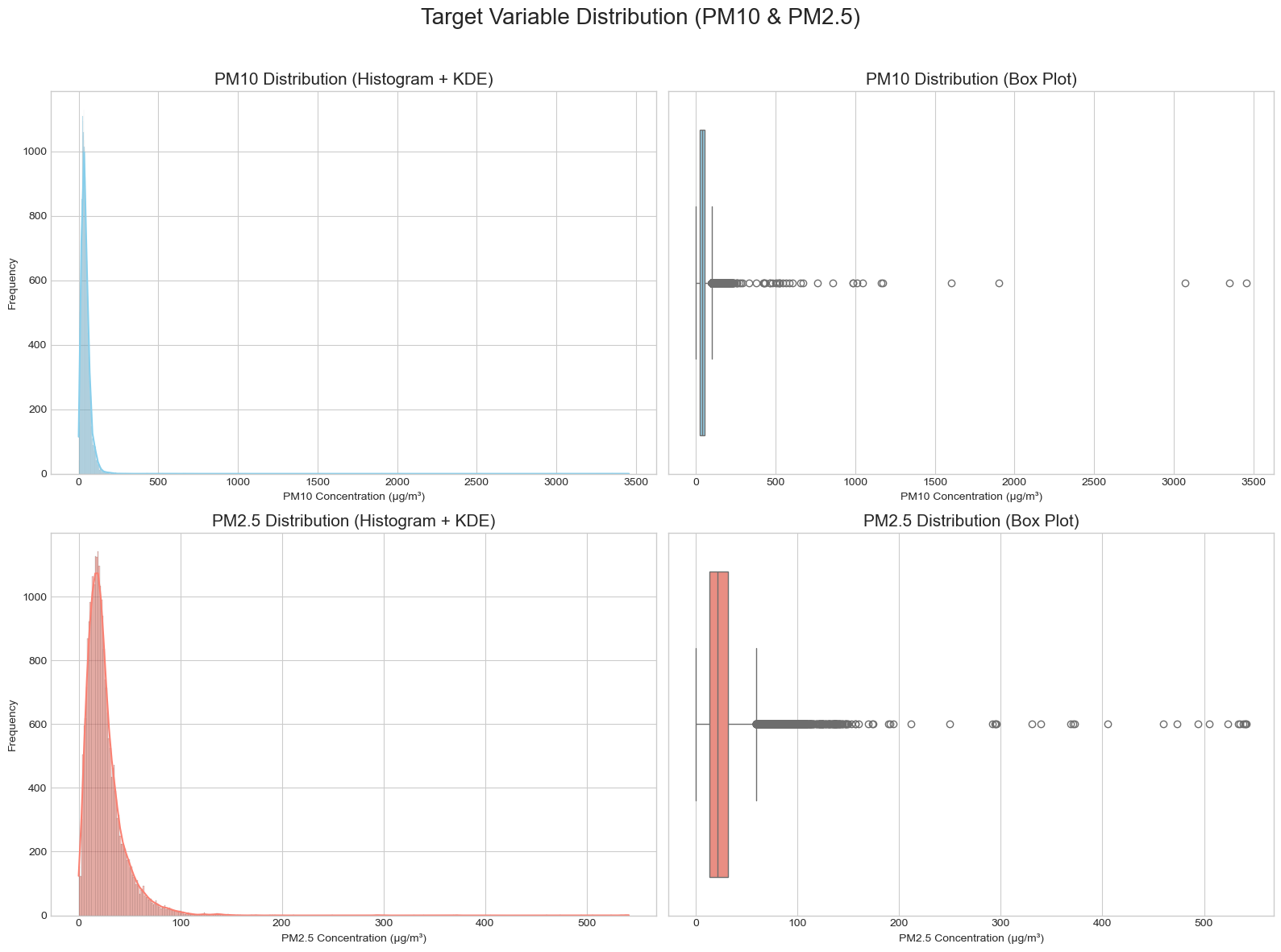
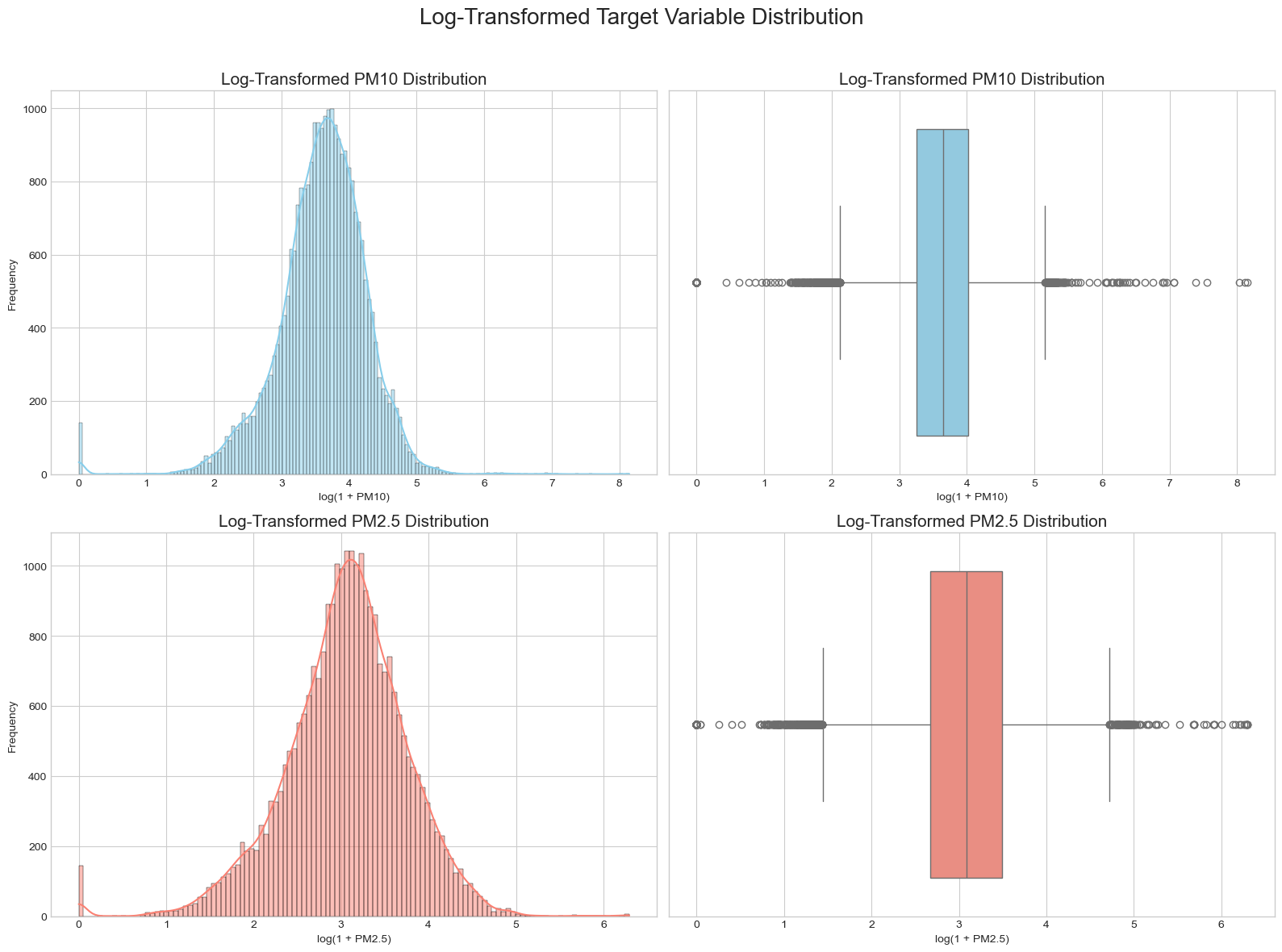
PM10과 PM2.5는 모두 낮은 농도 구간에 데이터가 많이 몰리고 오른쪽 꼬리가 긴 분포를 보였습니다. 극단적으로 높은 값이 모델 학습에 과도한 영향을 줄 수 있어 로그 변환을 적용했고, 변환 이후 분포가 더 안정적인 형태로 바뀌었습니다.
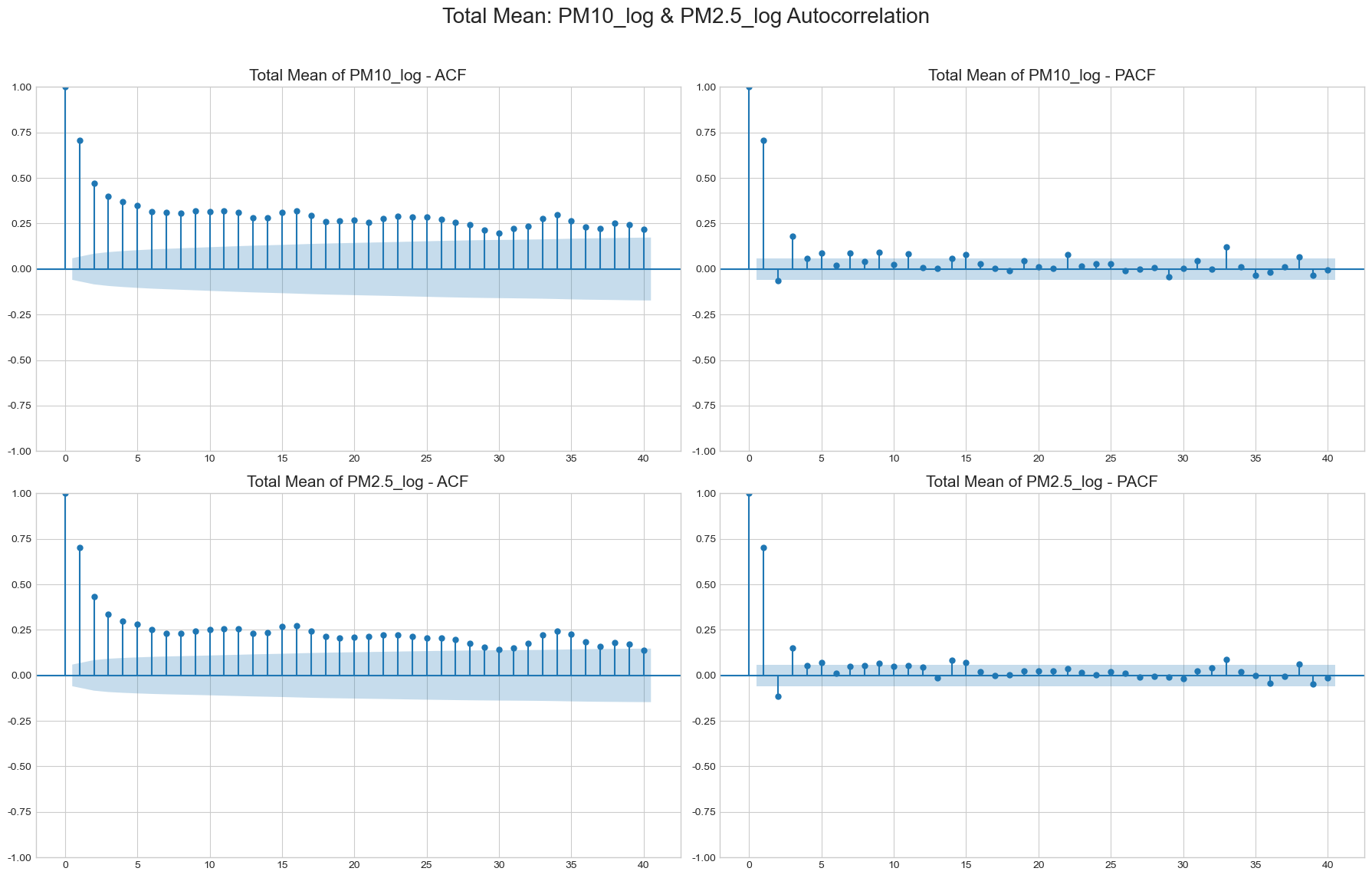
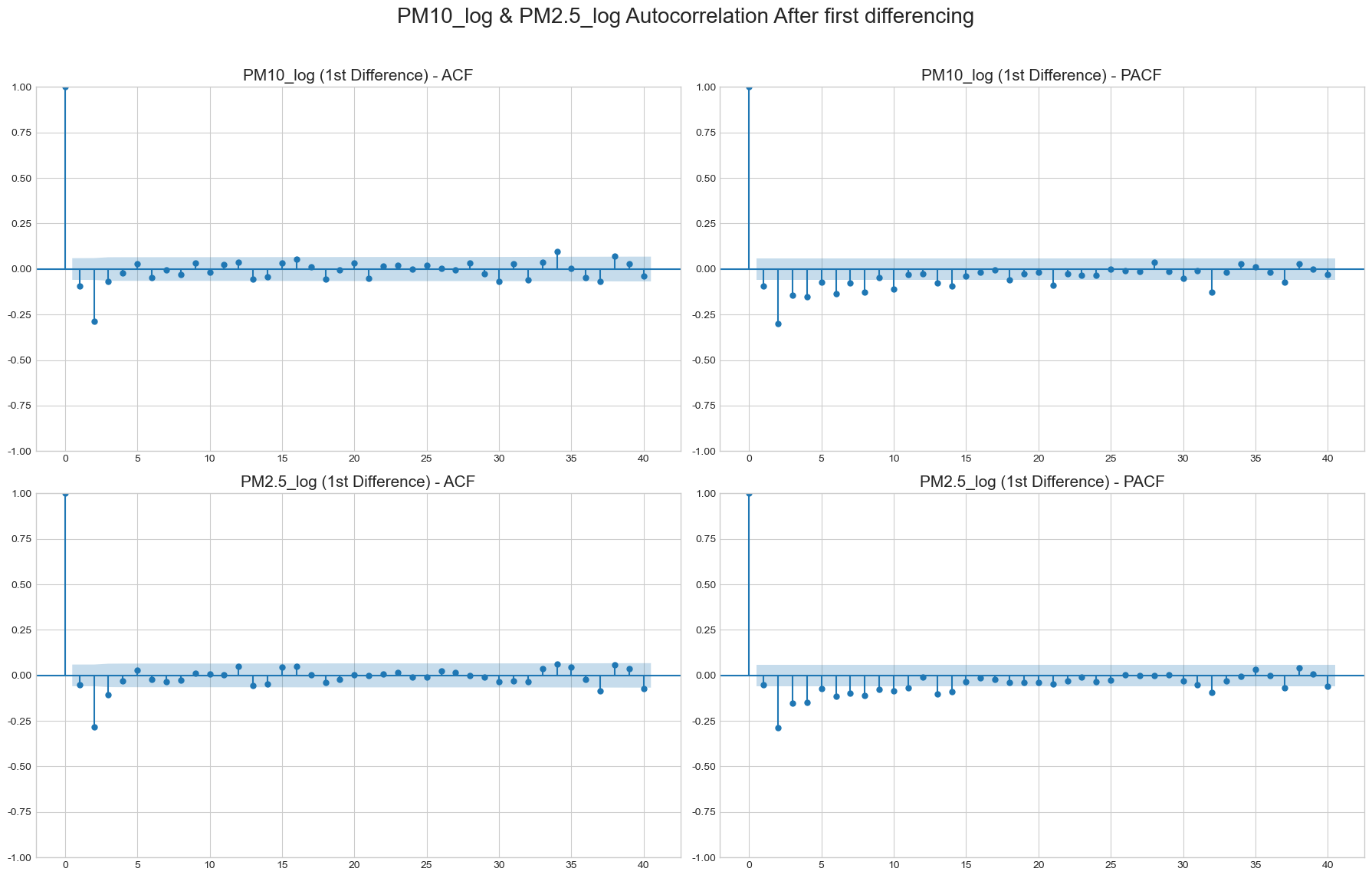
자기상관 분석에서는 로그 변환된 타겟 변수의 ACF가 천천히 감소해 추세와 비정상성이 존재함을 확인했습니다. PACF는 lag 1 이후 급격히 감소해 직전 시점의 영향이 강하다는 점을 보여주었습니다. 이후 1차 차분을 적용해 추세를 제거했고, ACF/PACF 절단 패턴을 바탕으로 ARIMA 계열 모델의 차수를 탐색했습니다.
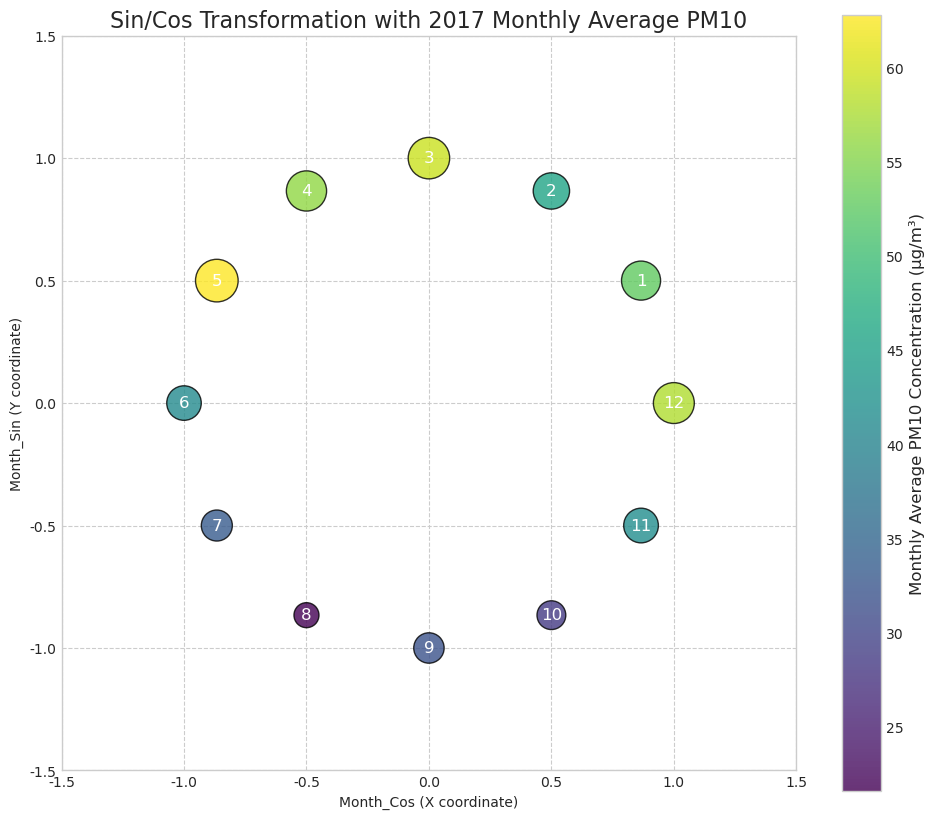
계절성도 뚜렷했습니다. PM10과 PM2.5 모두 겨울과 봄에 평균 농도가 높고 여름에 낮았습니다. PM10은 봄철, PM2.5는 겨울철에 상대적으로 높은 패턴을 보였고, 이는 황사, 대기 정체, 난방, 강수와 대기 순환의 차이와 연결해 해석했습니다. 이러한 반복 구조를 반영하기 위해 월, 계절, 요일 변수는 sin/cos 기반 순환형 변수로 변환했습니다.
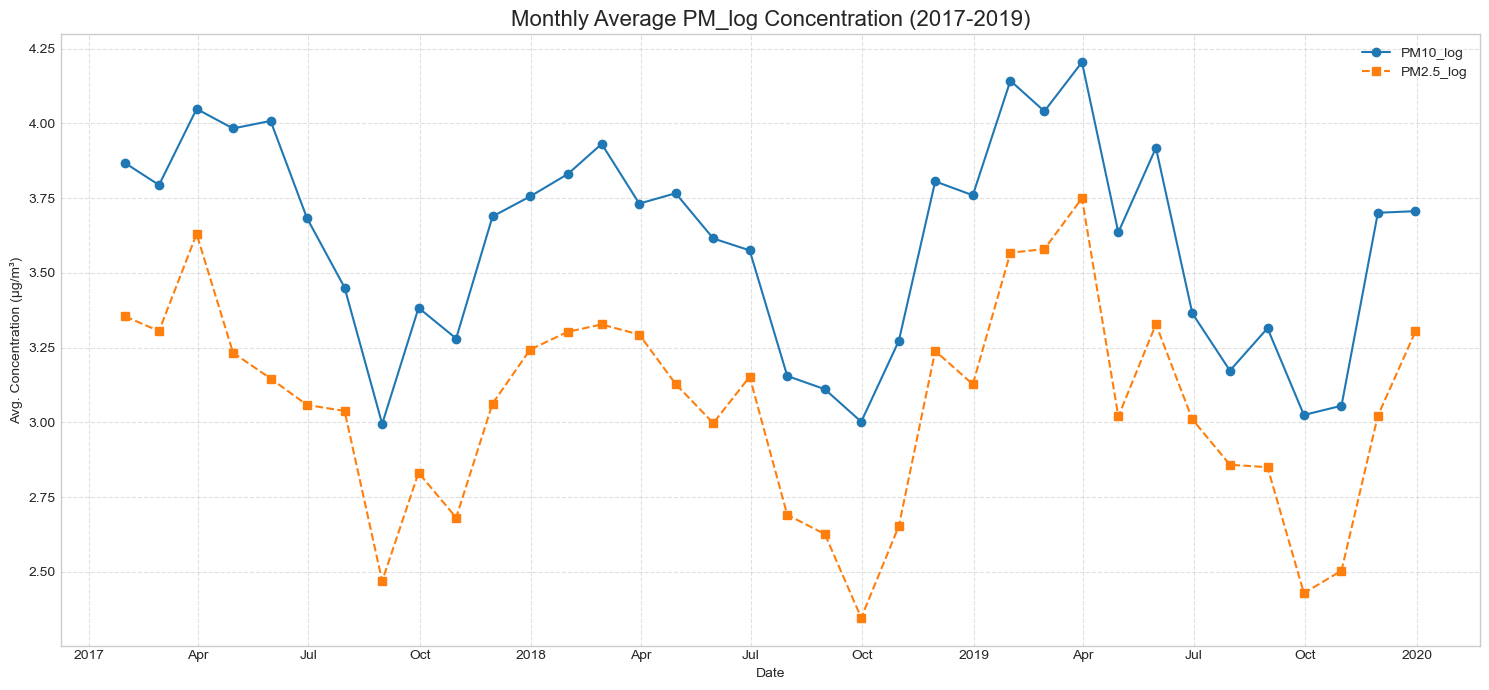
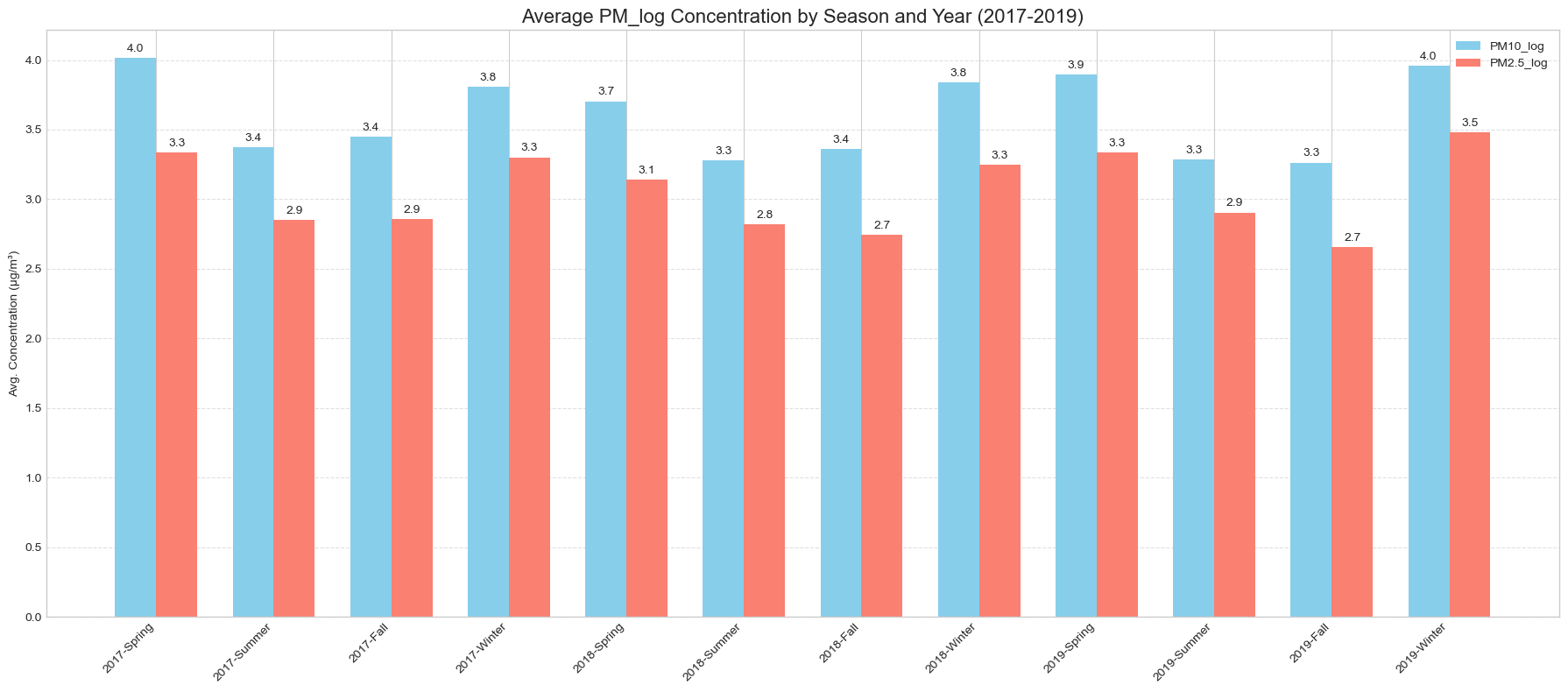
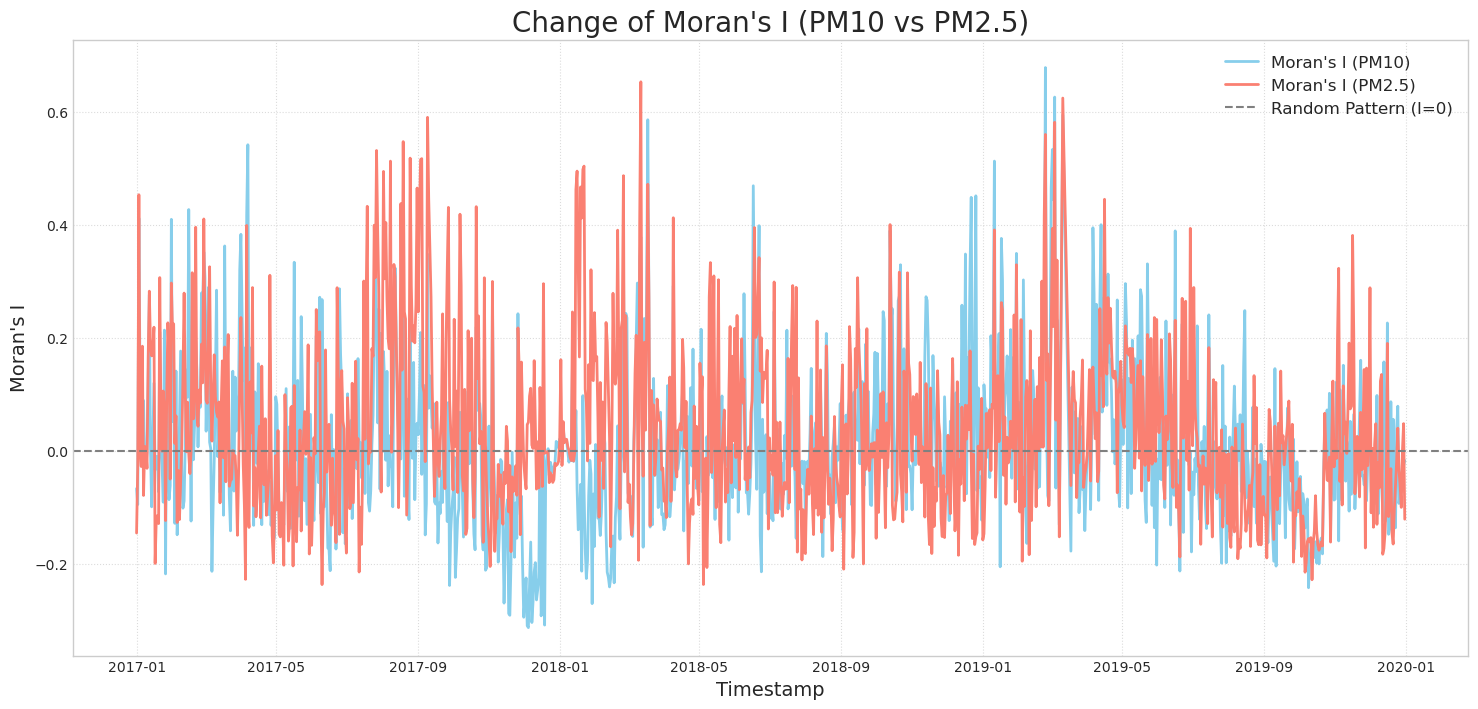
공간적 패턴도 별도로 확인했습니다. 전체 기간 평균 기준 PM2.5의 Moran’s I는 0.2320이고 p-value는 0.0120으로, 약하지만 통계적으로 유의한 양의 공간 자기상관이 있었습니다. 반면 PM10의 Moran’s I는 0.0290, p-value는 0.2270으로 유의한 공간 자기상관이 뚜렷하지 않았습니다. 계절별로는 겨울과 봄에 Moran’s I가 높아지는 경향이 있어, 공간 구조가 계절에 따라 달라진다는 점을 모델 변수에 반영했습니다.
접근 방법
모델링은 네 가지 후보를 비교하는 방식으로 진행했습니다.
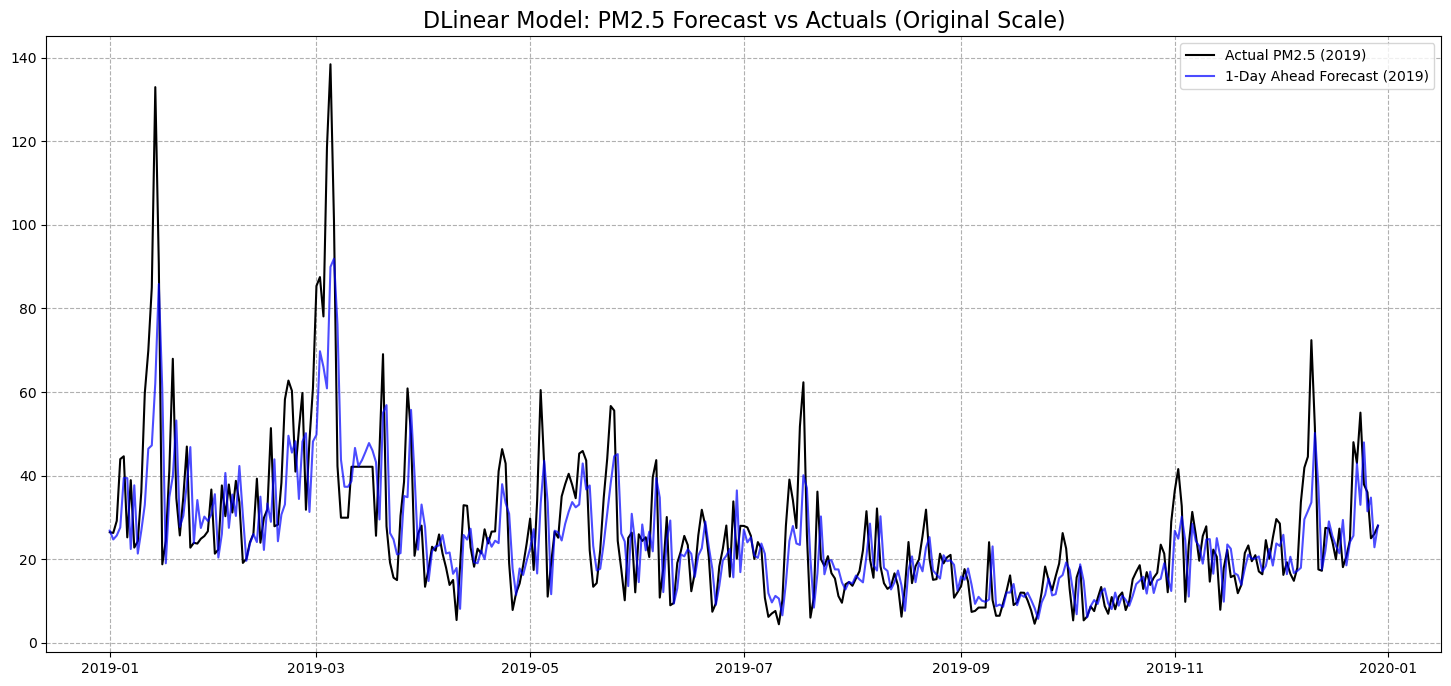
SARIMA: 미세먼지 농도 자체의 추세와 계절성을 반영하는 베이스라인 시계열 모델SARIMAX: 기온, 시공간 파생 변수 등 외생 변수를 포함한 시계열 모델LightGBM: 비선형 관계와 변수 간 상호작용을 학습하는 트리 기반 모델DLinear: 시계열을 trend와 remainder로 분해한 뒤 선형 레이어로 예측하는 딥러닝 모델
EDA 결과는 feature engineering으로 연결했습니다. 인접 측정소의 평균 농도를 나타내는 spatial lag 변수를 만들고, 공간적 군집이 겨울과 봄에 강해지는 패턴을 반영하기 위해 계절 상호작용 변수도 추가했습니다. 최종적으로 PM10_spatial_lag, PM2.5_spatial_lag, PM10_sl_ws, PM10_sl_sf, PM2.5_sl_ws, PM2.5_sl_sf 같은 변수를 구성했습니다.
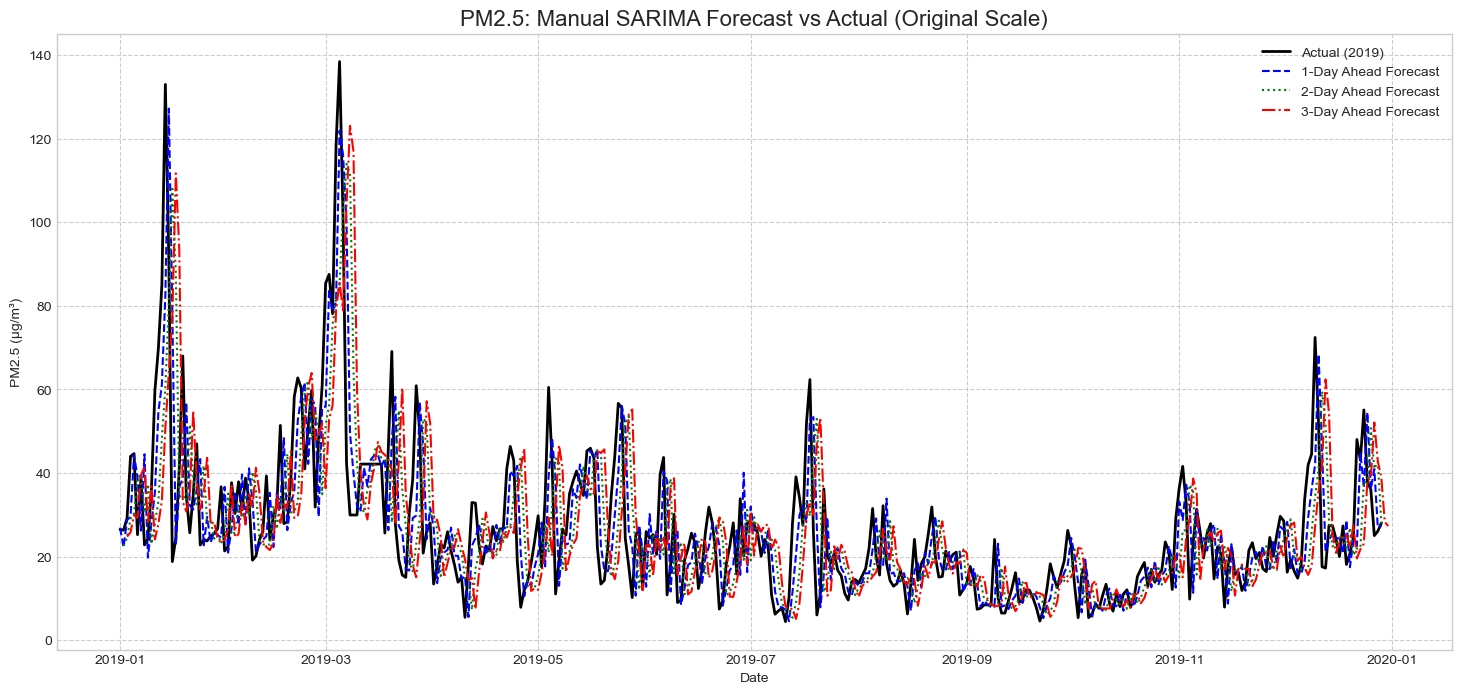
SARIMA는 파라미터 탐색 결과 PM2.5 기준 SARIMA(2,1,0)(1,1,1)[7]을 사용했습니다. SARIMAX는 외부 변수가 일부 계절성을 설명하면서 SARIMAX(2,1,0)(0,1,1)[7] 구조가 선택되었습니다.
성과(성능)
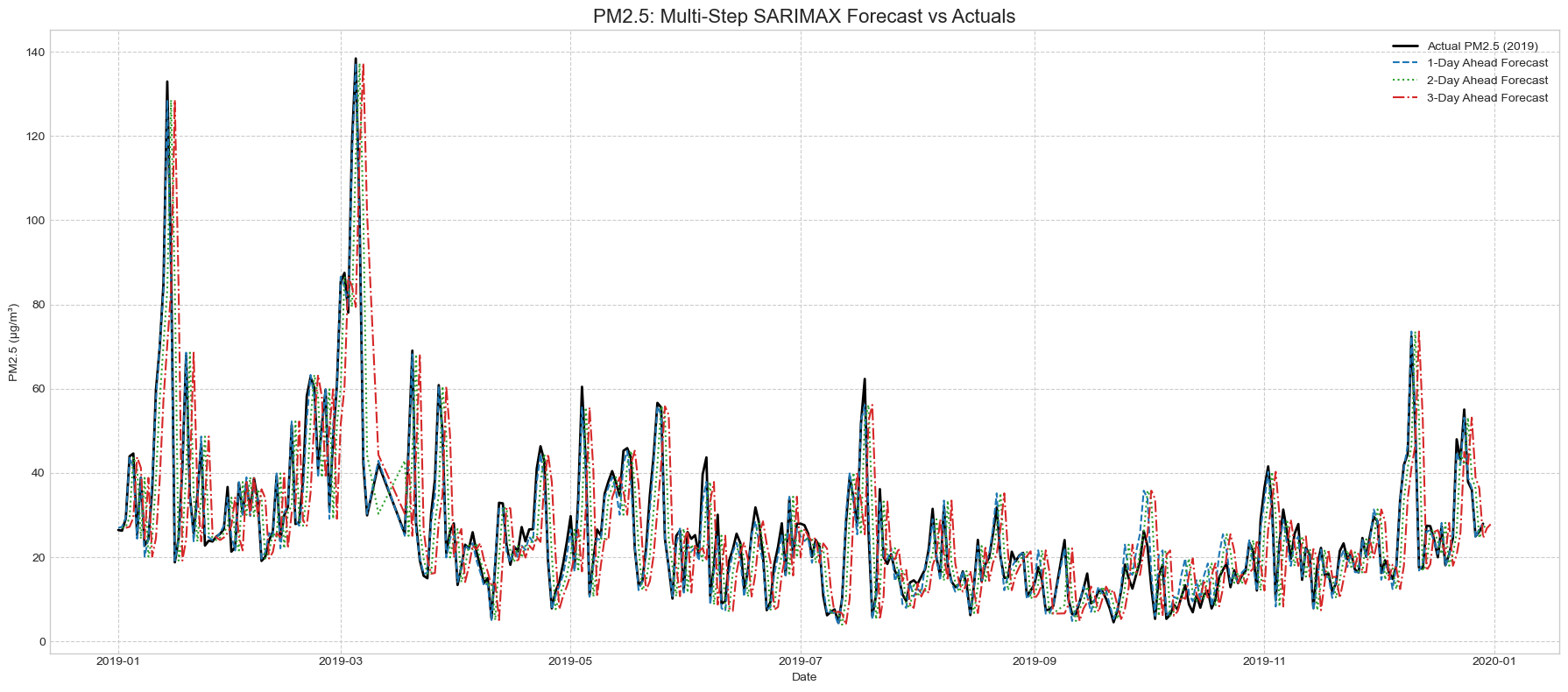
1일 후 예측 기준으로 PM2.5와 PM10 모두 SARIMAX가 가장 좋은 성능을 보였습니다.
| Model | PM2.5 MAE | PM2.5 RMSE | PM10 MAE | PM10 RMSE |
|---|---|---|---|---|
| SARIMA | 7.98 | 11.94 | 11.98 | 17.36 |
| SARIMAX | 7.15 | 10.44 | 10.92 | 16.65 |
| LightGBM | 9.72 | 13.93 | 14.44 | 20.61 |
| DLinear | 7.78 | 11.59 | 11.44 | 16.84 |
PM2.5에 대해 horizon별로 보면 SARIMAX는 1일 후 MAE 7.15, RMSE 10.44, 2일 후 MAE 9.33, RMSE 14.12, 3일 후 MAE 9.87, RMSE 15.45를 기록했습니다. 예측 시점이 멀어질수록 오차가 증가했지만, 단변량 SARIMA보다 전반적으로 낮은 오차를 보였습니다.
이 결과는 이 데이터셋에서 복잡한 비선형 모델보다, 시계열 패턴과 외부 변수의 관계를 명확하게 반영하는 SARIMAX가 더 적합했음을 보여줍니다. 특히 기온과 공간적 파생 변수처럼 EDA에서 확인한 외부 요인을 함께 넣는 것이 성능 개선에 중요했습니다.
느낀점
이 프로젝트를 하면서 가장 크게 느낀 점은, 시계열 예측에서는 모델 선택보다 데이터 구조를 먼저 이해하는 과정이 훨씬 중요하다는 점이었습니다. 분포가 치우쳐 있으면 로그 변환을 고민해야 하고, 자기상관이 강하면 차분과 AR/MA 구조를 확인해야 하며, 계절성과 공간성이 보이면 이를 변수로 바꿔 모델에 넣어야 합니다.
특히 미세먼지 데이터는 시간 패턴과 공간 패턴이 동시에 존재해 단순 회귀 문제처럼 접근하기 어렵습니다. EDA에서 발견한 계절성과 공간 자기상관을 실제 변수로 연결하고, SARIMAX가 그 정보를 활용해 성능을 개선하는 흐름을 확인한 점이 가장 의미 있었습니다.